Transformer is my need! [draft]
从基础开始学习transformer

Beijing: ☀️ 🌡️+32°C 🌬️↓4km/h
写在前面
Attention 解决的问题:
- 输入是一排向量
- 输入的 sequence 的长度不固定
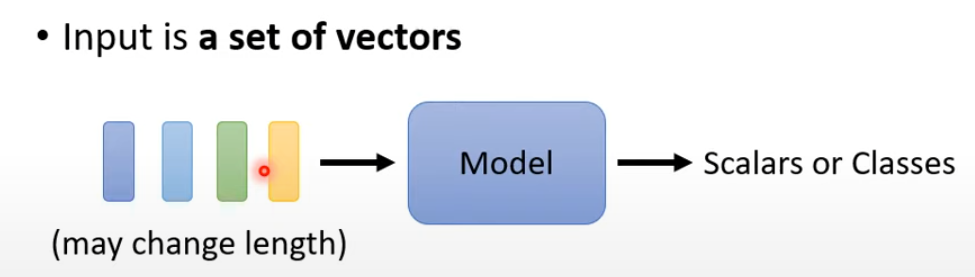
模型输入:
- 输入是一句文字
- 将文字可以适用 One-hot Encoding 编码
- Word Embedding 编码句子
- 输入是一段声音信号
- 确定一个窗口分割声音讯号,一般是 25ms,每次向右移动 10ms
- 再将声音信号变为向量
- 图(graph)也是一个一堆向量组成
- 分子可以表示为 graph
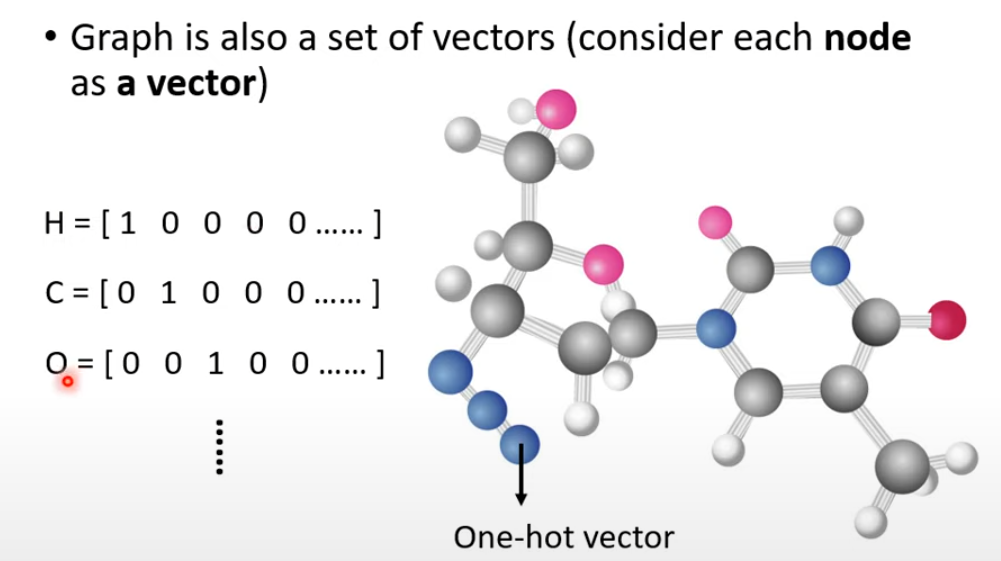
- 每个向量都有对应的 label
- 输入输出等长
- 词性标注
- graph 中的商品推荐或者分子特性预测
- 整个 sequence 输出一个 label
- 情感分析 sentiment analysis
- 语音辨识
- 分析一个分子结构的特性
- 输出不等长的 seq,也就是 seq2seq
- 翻译
- 对话
- 语音辨识
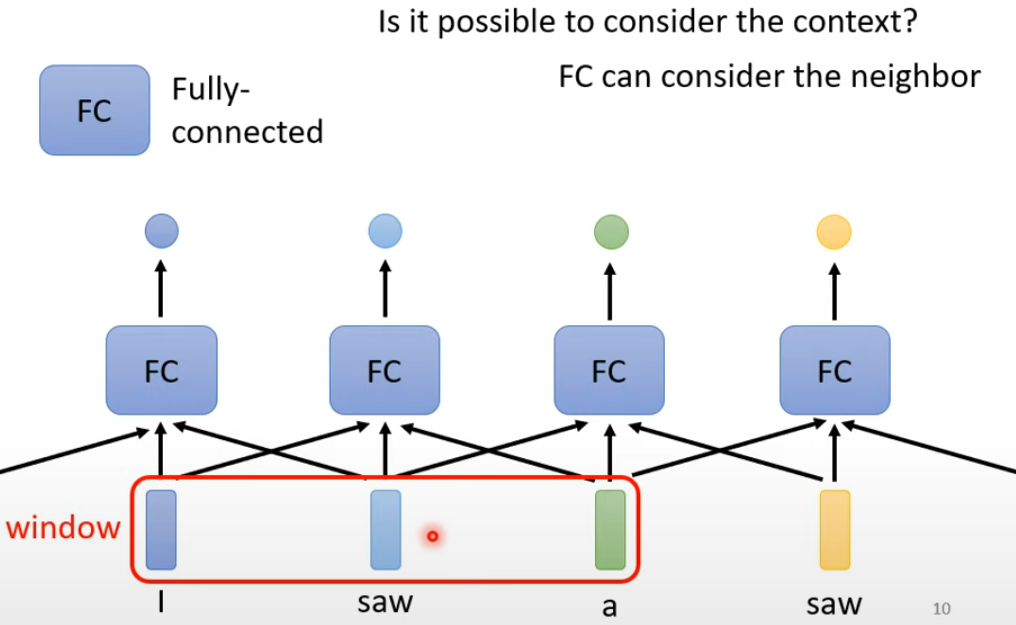
FC 对词性标注问题思考:
- 首先考虑的是输入单个词直接给你某个词对应的词性,但在不考虑上下文的情况下,输入两个 saw 给出的是相同的含义
- 设置一个 window,每次输入再添加前后五个词的输入,如果输入是很长的一个 sequence,带来的问题就是必须开最长 seq 的 window 才能覆盖所有 seq,可能会导致过拟合
Attention is all you need
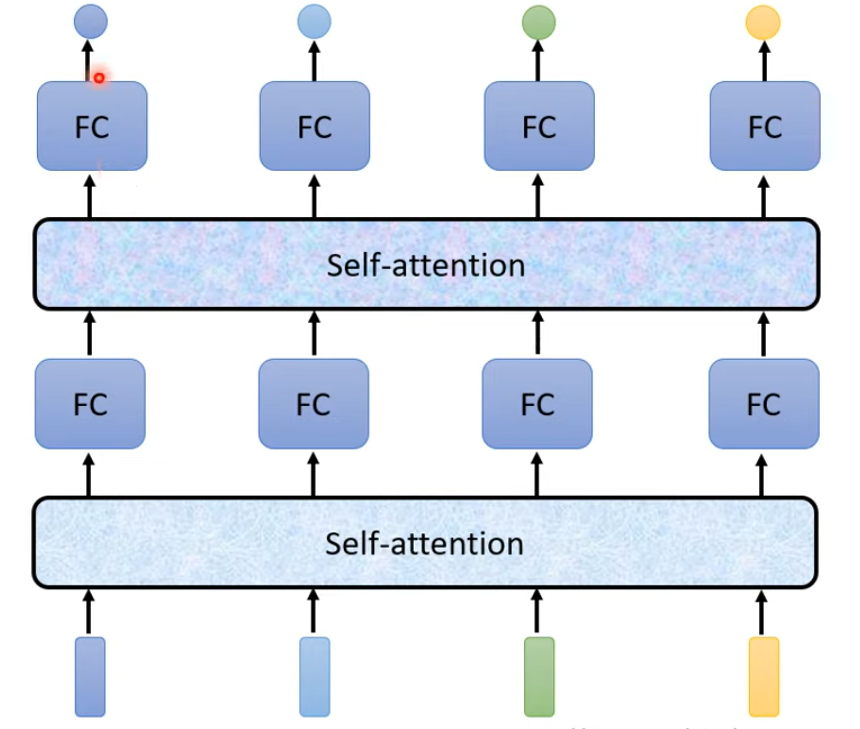
对于一个 sequence 的输入,我们先在此计算两个向量的相关程度:
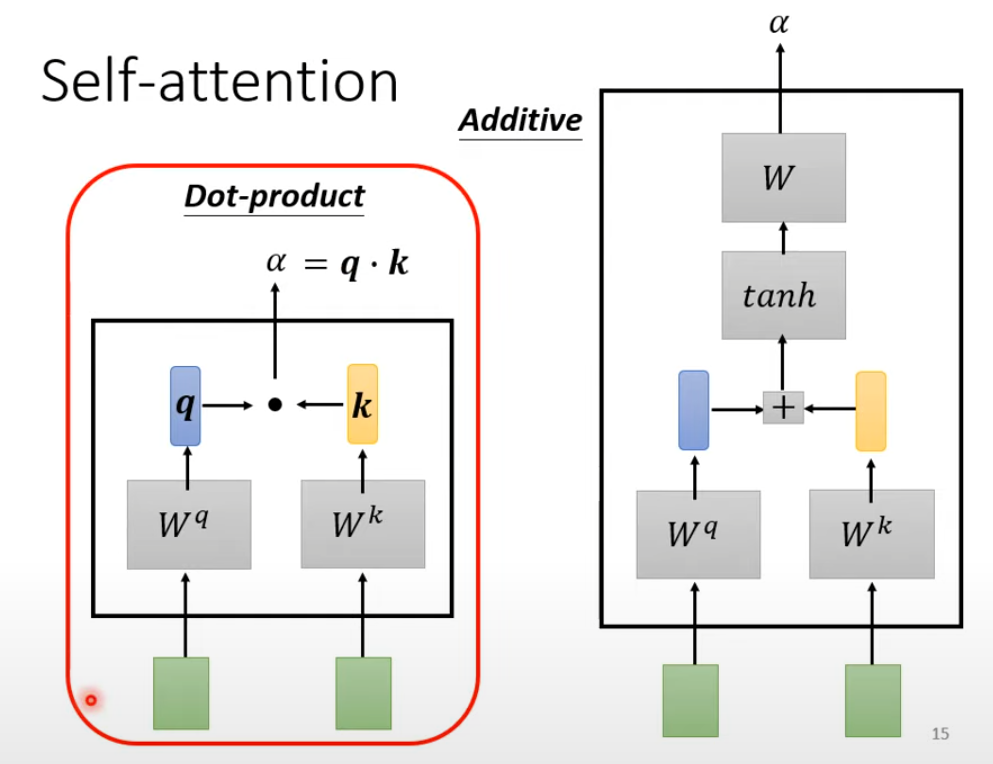
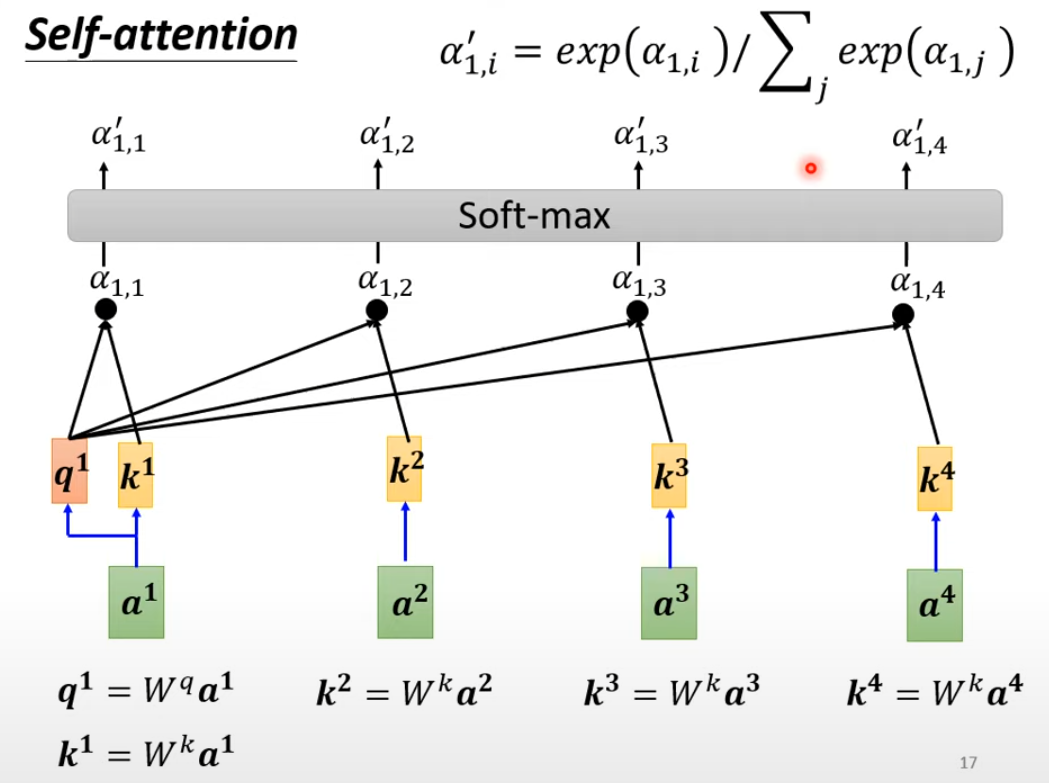
最终向量的分数越高,权重加和以后的值就越接近:

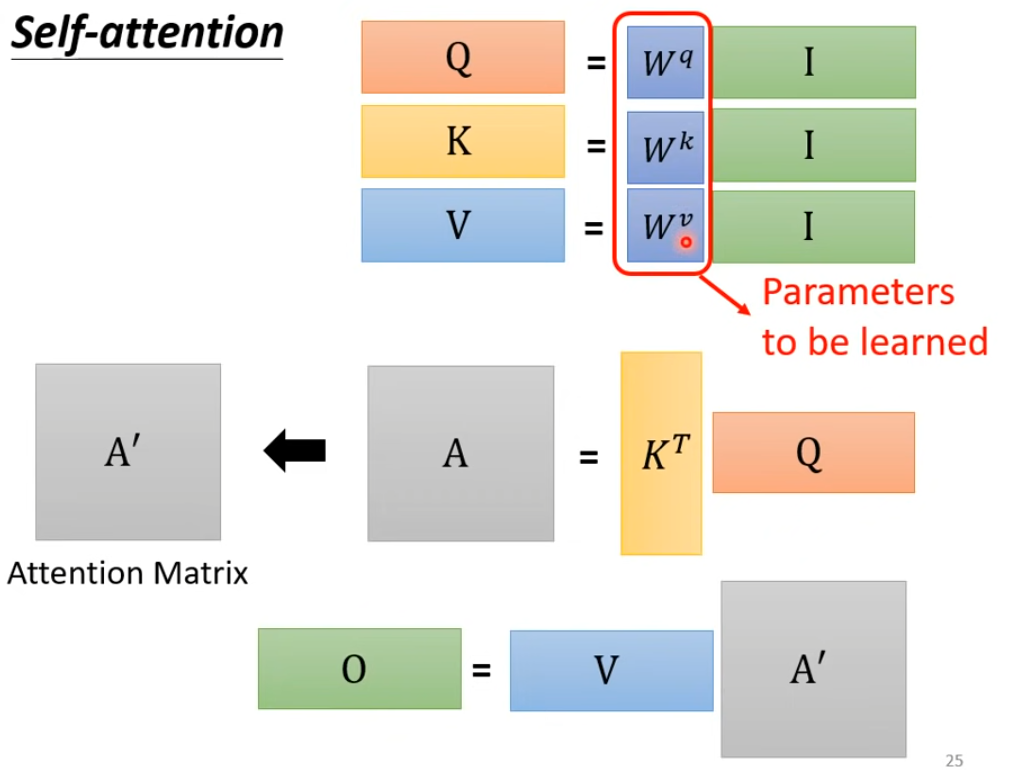
矩阵运算角度理解 attention 的 input 到 output:
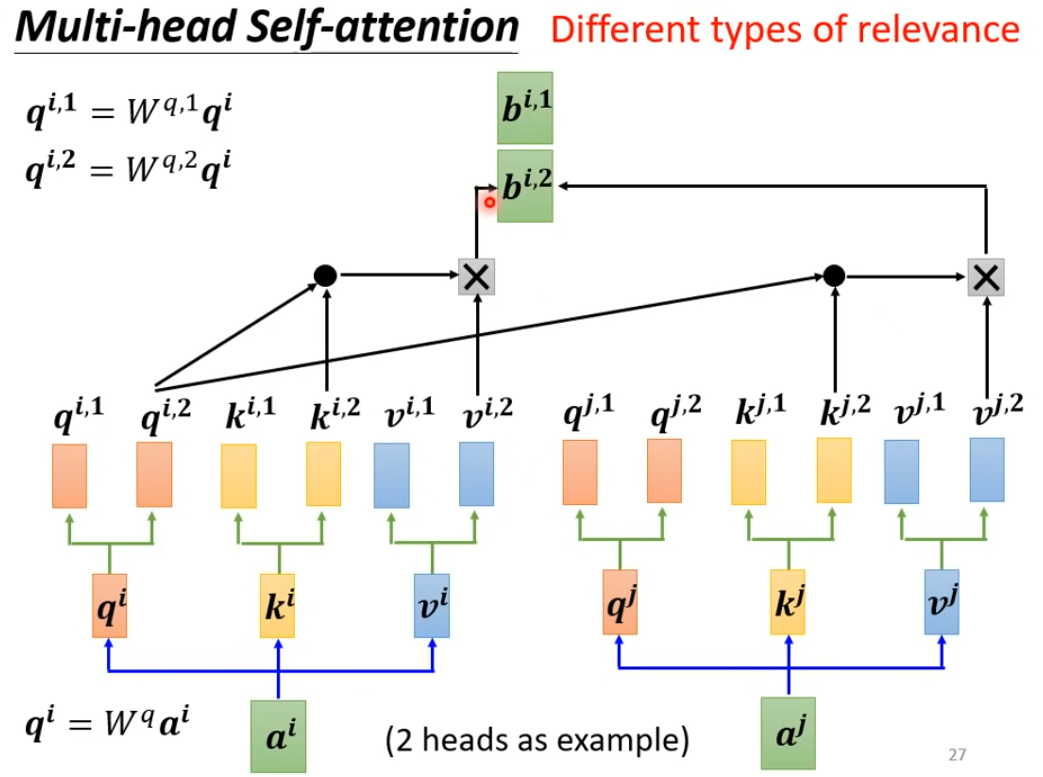
多头注意力机制(multi-head attention)
上述的 self-attention 没有位置的资讯,根据下游任务的需要,考虑添加位置资讯
self-attention 应用场景
- 语音辨识
- 图像应用
- CNN 就是 self-attention 的特例,该文章适用[1911.03584] On the Relationship between Self-Attention and Convolutional Layers
- 训练数据在较多的情况下,self-attention 的效果可能优于 CNN,可以考虑相结合使用[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
RNN 与 Self-attention 区别:
- RNN 在运算过程中,之前的信息比较容易丢失
- RNN 无法并行计算,一次计算所有的 output
- RNN 与 Self-attention 的关系[2006.16236] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
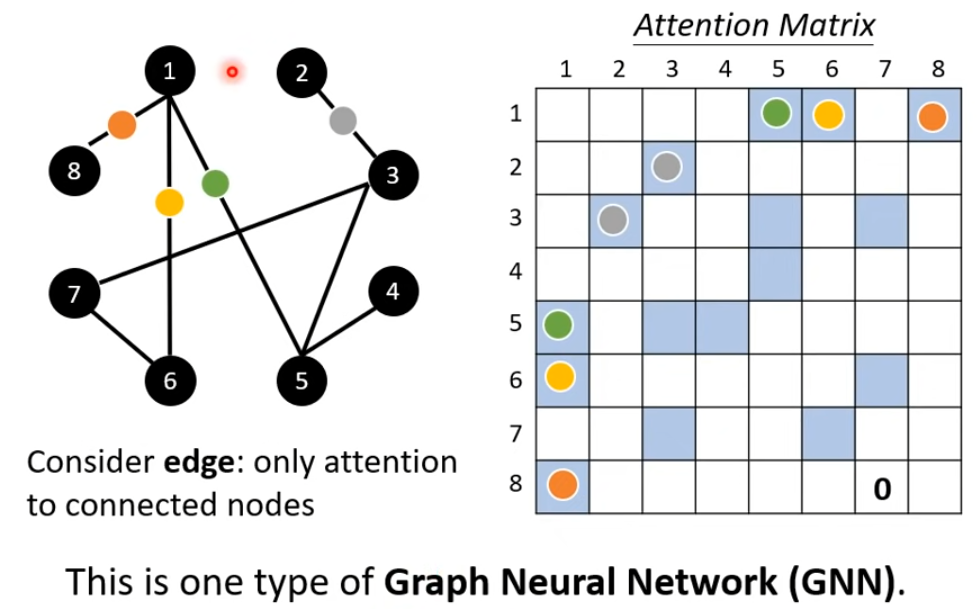
Self-attention for graph:构造好的 graph 实际已经包含节点之间的连接关系,在计算 Attention-matrix 的时候可以只考虑已经连接的节点之间的 attention 分数
Self-attention 变形,主要目的是减少运算量,提高模型表现[2011.04006] Long Range Arena: A Benchmark for Efficient Transformers
Transformer
Encoder
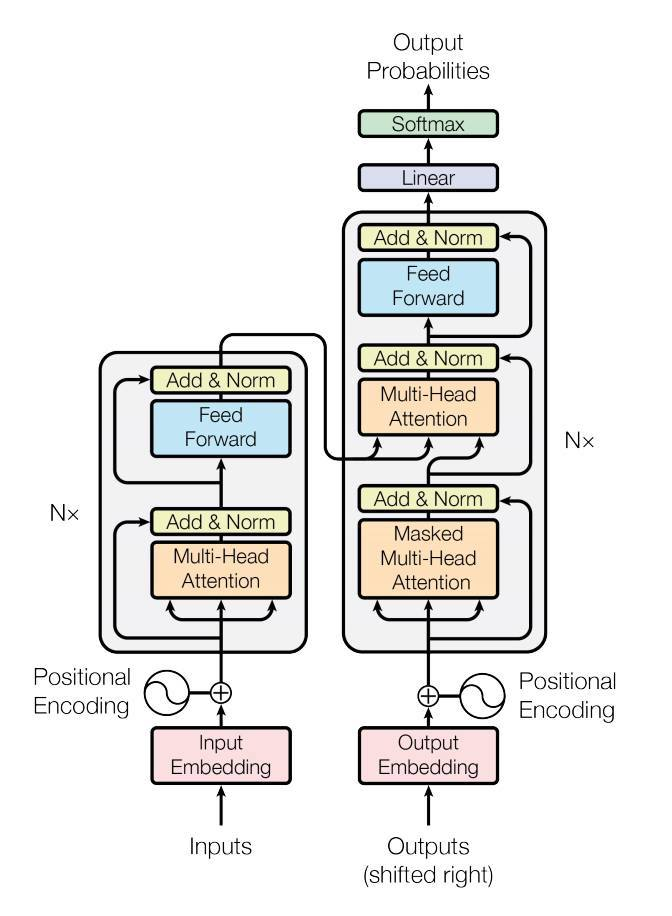
- Add&Norm – Residual + Layer norm
- Feed Forward – FCN
- Learn more:
Decoder
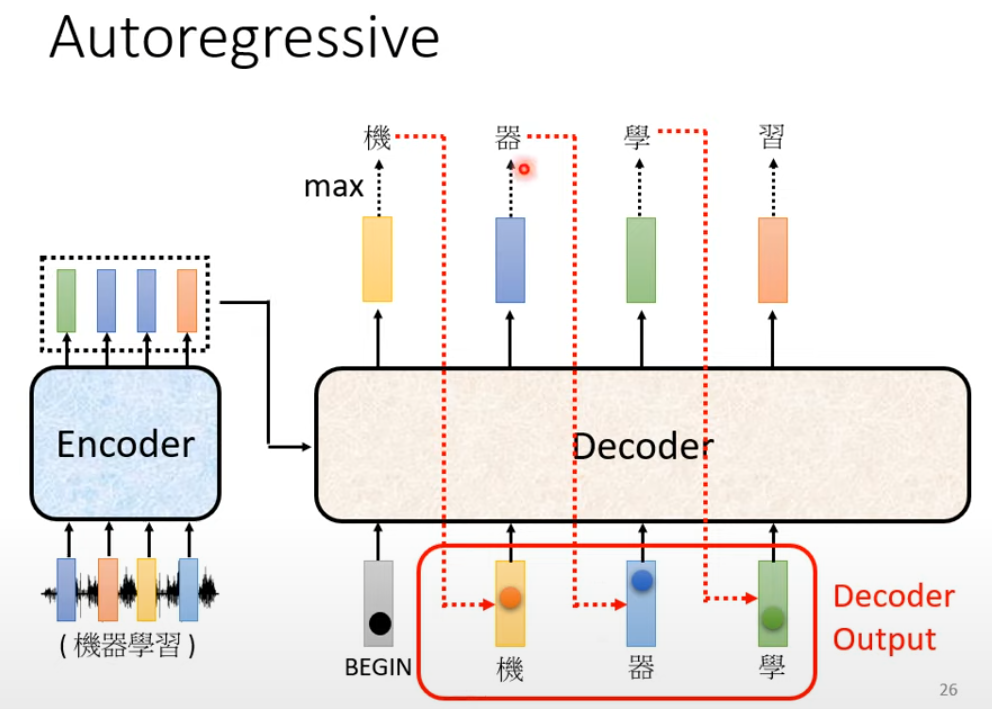
- Decoder 前一时刻以及的输出将作为下一时刻的输入,输入 Decoder 来生成下一个词
- 当掩盖住 Decoder 中间的
Add Norm & Multi-head Attentioin,和 Encoder 部分几乎保持一致
Masked self-attention

- 在 Decoder 生成 sequence 的过程中,并没有$a^3,a^4$产生,也就相当于之后的 token 被掩盖住了,因此只需要关注之前的 seq
- Decoder 必须自己决定自己输出的长度
- 对于 auto regressive 类型需要一个比较特殊的 token–
END,当 Encoder 输出到 END 时,表示结束
- 对于 auto regressive 类型需要一个比较特殊的 token–
Decoder - Non Autoregressive(NAT)
- How to decide the output length for NAT decoder?
- Another predictor for output length
- Output a very long sequence, ignore tokens after END
- Advantage: parallel, controllable output length
- 劣势:一般表现比 AT 的 decoder 效果略差
Encoder 与 Decoder 连接
Cross Attentiion
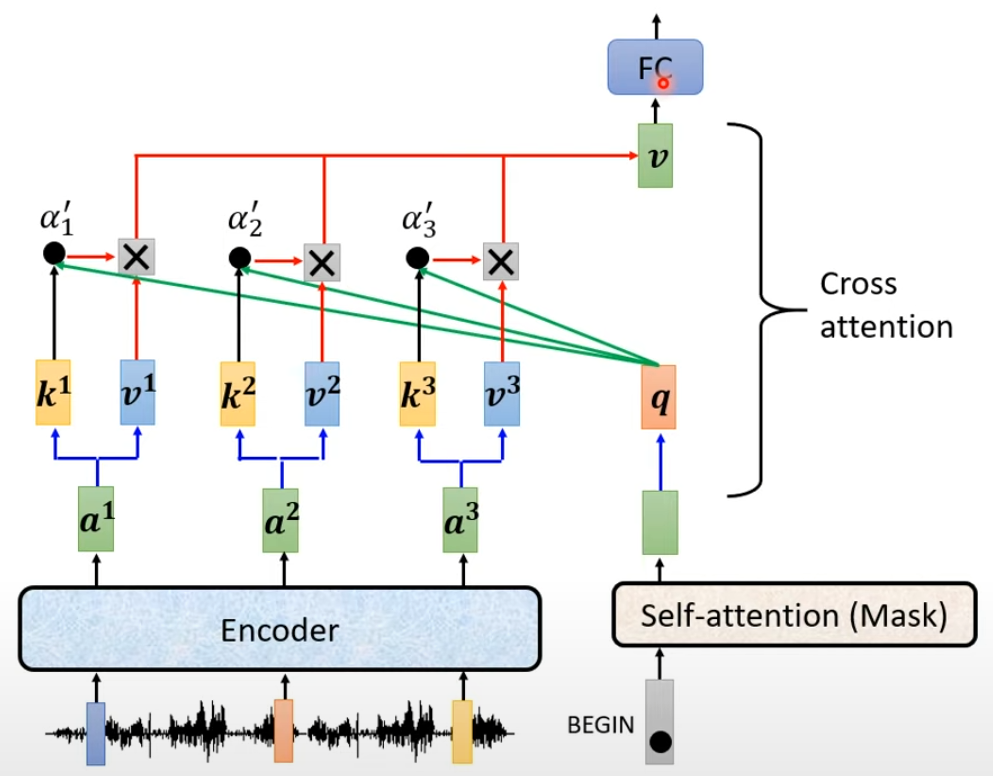
- q 来自于 Decoder,k 和 v 来自于 Encoder
- 一个大模型的训练,它同时有很多层的 Encoder 和 Decoder,原始的论文中每层 Decoder 拿到的都是最后一层 Encoder 的 k 和 v,可以存在不同的组合方式[2005.08081] Rethinking and Improving Natural Language Generation with Layer-Wise Multi-View Decoding
Training
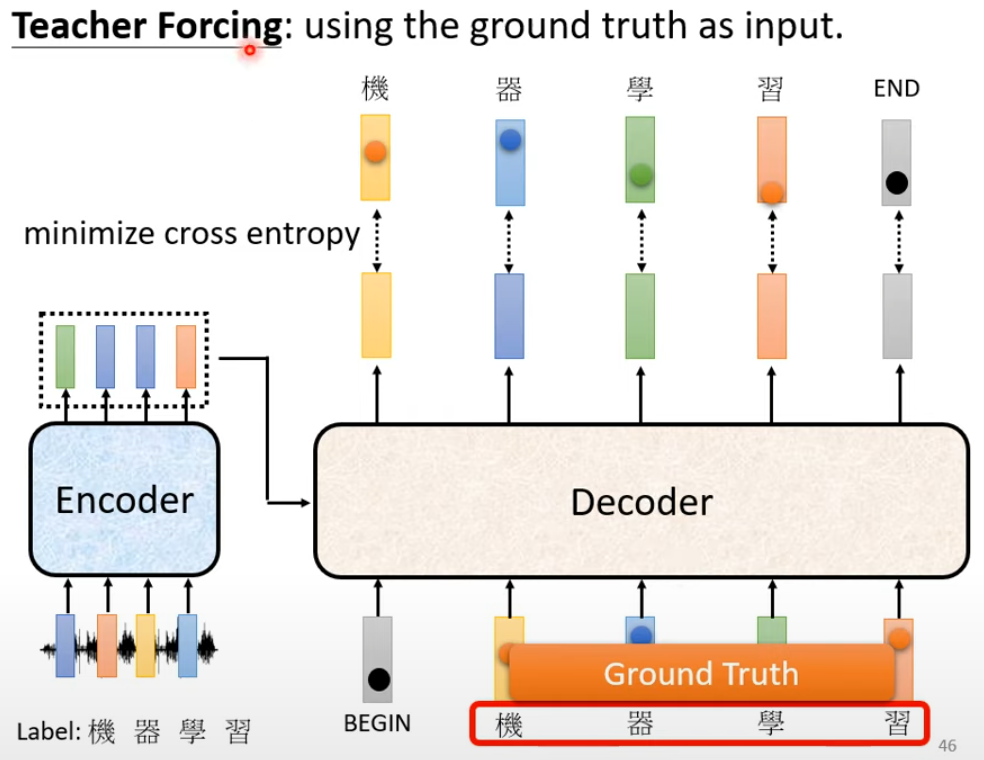
该图是一个语音辨识的图例,我们希望对输入的语音进行辨识:
- Decoder 的输入是正确答案
- 当 decoder 接收到 begin 这个 token 的时候,期望 output 第一个输出是“机”,正确的答案将被表示为整个词典关于“机”这个字的 one-hot 表示
- 而 decoder 的第一个位置的输出通过 softmax 将被表示为一个机率分布,优化的目标就是该词于正确答案的交叉熵
- 整体模型优化目标是整个 seq 的交叉熵的和最小
在实际的测试集中,并没有提供的正确的答案,存在 mismatch
Tips
Copy Mechanism
- chat-bot
- User:你好,我是库洛洛
- Chat-bot:库洛洛你好,很高兴认识你
- summarization
- 训练 seq2seq 文本摘要[1704.04368] Get To The Point: Summarization with Pointer-Generator Networks
- 一般而言,seq2seq 任务对数据量的要求会比较大,例如 SCI 文本摘要而言,则至少在百万篇文章
Guided Attention
一般而言,我们在做语音合成或是语音辨识的时候,attention score 的计算都是从左到右的,因此可以加入一些限制
- Monotonic attention
- Location-aware attention
Beam Search
- seq 的生成基本依赖于计算的注意力分数,假设存在两条 seq 的路径 A 和 B,尽管 A 开始的 attention score 可能相对低一点,但是后期的 attention score 会高,B 路径整个过程都会相对均匀一点
- 如果按照常规计算最大 attention score 的 seq,称之为 Greedy Decoding
- 使用 Beam Search 在不同的任务上存在不同的表现,根据任务本身的特性决定,比如语音辨识,答案相对唯一,Beam Search 表现相对较好,当需要发挥一些创造力的任务的时候,也就是答案不唯一的时候,BS 并没有那么适用
- [1904.09751] The Curious Case of Neural Text Degeneration
Optimizing Evaluation Metrics?
- 模型在训练的过程中使用的是交叉熵,但是最终模型评分是 BLEU score
- 交叉熵和 BLUE score 之间没有绝对的相关性,并非交叉熵越低,所对应的 BLUE score 越高
- 最终模型的选择一般是在 validation set 上 BLEU score 最高的模型
- BLEU 不能进行微分,无法作为 trianing 过程中的 loss
- when you don’t know how to optimize, just use reinforcement learning(RL)[1511.06732] Sequence Level Training with Recurrent Neural Networks
Exposure bias
- Decoder 在训练的时候,如果在语料正确的情况下,看到的都是正确的东西,但是在测试的时候当输入是一些带有错误的输入时,可能会导致有较大输出有较大偏差
- 思考方向:Decoder 训练的过程中加入一些 Noise
- Original ScheduledSampling[1506.03099] Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
- Scheduled Sampling forTransformer[1906.07651] Scheduled Sampling for Transformers
- Parallel ScheduledSampling[1906.04331] Parallel Scheduled Sampling
参考文献
- 機器學習 2021:自注意力機制 (Self-attention) (上) - YouTube
- 機器學習 2021:自注意力機制 (Self-attention) (下) - YouTube
- Paper | Attention Is All You Need
- Large Language Models, GPT-1 — Generative Pre-Trained Transformer | by Vyacheslav Efimov
- Large Language Models, GPT-2 — Language Models Are Unsupervised Multitask Learners | by Vyacheslav Efimov
- Large Language Models, GPT-3: Language Models are Few-Shot Learners | by Vyacheslav Efimov
- What is Relative Positional Encoding | by Ngieng Kianyew | Medium
- Paper | GPT-1 | Improving Language Understanding by Generative Pre-Training
- Paper | GPT-2 | Language Models are Unsupervised Multitask Learners
- Paper | GPT-3 | Language Models are Few-Shot Learners
- OpenAI Blog | GPT-1 | Improving language understanding with unsupervised learning
- OpenAI Blog | GPT-2 | Better language models and their implications
- OpenAI Blog | GPT-3 Language models are few-shot learners
- Dive into deep learning:Attention Mechanisms and Transformers
- Attention? Attention! | Lil’Log
- The Transformer Family | Lil’Log
- The Transformer Family Version 2.0 | Lil’Log
- Master Positional Encoding: Part I | by Jonathan Kernes | Towards Data Science
- Master Positional Encoding: Part II | by Jonathan Kernes | Towards Data Science
- Understanding Rotary Positional Encoding | by Ngieng Kianyew | Jan, 2024 | Medium
- Position Information in Transformers: An Overview | Computational Linguistics | MIT Press
- Paper | The Impact of Positional Encoding on Length Generalization in Transformers
- How to generate text: using different decoding methods for language generation with Transformers
- The Illustrated GPT-2 (Visualizing Transformer Language Models) – Jay Alammar – Visualizing machine learning one concept at a time.
- Text generation strategies
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) – Jay Alammar – Visualizing machine learning one concept at a time.
- A Visual and Interactive Guide to the Basics of Neural Networks – Jay Alammar – Visualizing machine learning one concept at a time.
- Generating Human-level Text with Contrastive Search in Transformers 🤗
💬 评论