廖雪峰 Python 学习笔记 [draft]
Python 预备知识
进入Python 官网 可以看到它的主页面写着这样两句话,“Python 的便利性使得它成为机器学习和人工智能领域最流行的编程语言。Python 的灵活性满足从笔记本到计算机集群的任意规模机器学习或人工智能”,这两句话充分表明了 Python 的特点”便利性“和”灵活性“。其中”便利性“主要体现在:比如完成同一个任务,C 语言可能要写 1000 行代码,Java 要写 100 行,而 Python 可能只要 20 行就可以达成目标。
Python 基础
- Python 有适合自己的一套语法体系,编译器或者解释器就是把符合语法规则的 Python 转成 CPU 能够执行的机器码
- Python 的注释通常是以
#开头的 - 约定俗成的缩进为四个空格
基本数据类型和变量
整数
- Python 可以处理整数,例如
1、10、100 - 计算机使用的是二进制,有时候使用十六进制比较方便,因此用
0x表示十六进制,例如:0xff00 - 对于较大的数字,Python 允许使用
_进行分隔,可以写为10_000_000,十六进制可以写为0xa1b2_c3d4
浮点数
- 浮点数可以用科学计数法表示 $1.23 \times 10^9$ 可以表示为
1.233e - 整数运算永远是精准的**(除法也是)**,浮点数运算可能存在四舍五入误差
字符串
- 字符串是以
''或者""表示的 - 字符串中的反斜杠
\表示转义符,可以用来表示一些特殊字符 - 当字符串用
r""表示的时候,默认不进行转义 - 字符串有很多行时候,可以三个单引号如
'''str'''进行表示
# 不进行转义
print(r'''hello,\n
Python''')
hello,\n
Python
布尔值
- 布尔值用
True和False进行表示 - 两种布尔值可以用逻辑的
and、or、not进行连接
空值 None
- 空值
None是一个特殊的值,不能理解为0
字符串和编码
字符编码
- 计算机只能处理数字,使用字符串存在编码问题
- 最早设计 8 个 bit 为一个字节,因此一个字节表示最大整数为$2^8-1=255$
- 美国人设计用
ASCII编码表示 127 个字符 - 各国都有自己的标准,导致编码混乱
- 最终统一使用
Unicode进行编码,常用两个字节 - 由于
Unicode存在内存占用过大问题的,出现UTF-8编码,可以自动调控字节占用大小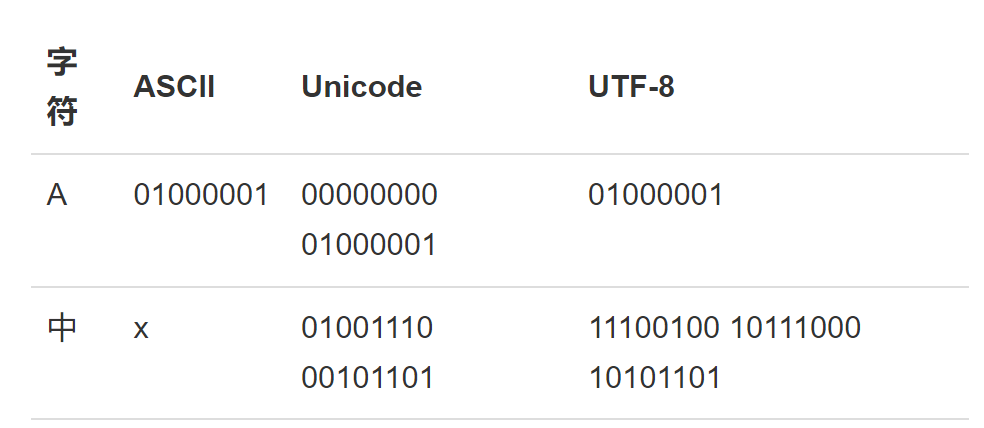
- 在计算机内存中,统一使用
Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码
Python 字符串
- 在 Python3 中,字符串是以
Unicode进行编码的,也就是 Python 支持多语言 - Python3 提供
ord函数获取字符串整数表示,chr()把编码转为字符 - Python 的字符串类型是
str,内存以Unicode表示,一个字符对应若干字节,在网络传输或保存到磁盘,以bytes字节表示
ord('国')
22269
chr(22269)
'国'
- Python 对
bytes类型用带b的前缀单引号表示,如x = b'ABC'
# 以Unicode表示的str可以编码为指定的bytes
print('abc'.encode('ascii'))
print('中文'.encode('utf-8'))
b'abc'
b'\xe4\xb8\xad\xe6\x96\x87'
# 解码从网络或者磁盘上读取的字节流
print(b'abc'.decode('ascii'))
print(b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8'))
abc
中文
-
Python 源码也是一个文本文件,因此我们需要指定读取方式为
utf-8的编码方式 -
Python 文件通常需要添加这两行
#!/usr/bin/env python3和\# -*- coding: utf-8 -*--
第一行注释是为了告诉 Linux/OS X 系统,这是一个 Python 可执行程序,Windows 系统会忽略这个注释
-
第二行注释是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码,否则,你在源代码中写的中文输出可能有乱码
-
-
确保你的编辑器使用
utf-8编码
格式化
%表示- 使用
%进行输出,后面使用()对应好变量顺序

%s永远起作用,可以将整数等转为字符串- 使用
%%表示%输出
- 使用
format()表示- 传入参数依次占据
{0}、{1}等
- 传入参数依次占据
f-string表示- 字符串如果包含
{str}就会以变量记性替换
- 字符串如果包含
"name: %s, age: %.2f" % ('xiaoming', 23.0)
'name: xiaoming, age: 23.00'
"name: {0}, age: {1:.2f}".format('xiaoming', 23.00)
'name: xiaoming, age: 23.00'
name = 'xiaoming'
age = 23.0
f"name: {name}, age: {age:.2f}"
'name: xiaoming, age: 23.00'
集合 list 数据类型
- list 是一种有序集合
people = ['li', 'mu', 'zhang']
people
['li', 'mu', 'zhang']
- 使用索引进行访问,从 0 开始,例如
li[0],最后一个元素为索引为-1
people[-1]
'zhang'
- 列表常见操作
# 列表添加元素到末尾
people = ['li', 'mu', 'zhang']
people.append('wang')
people
['li', 'mu', 'zhang', 'wang']
# 删除指定索引元素,默认为0
people = ['li', 'mu', 'zhang']
people.pop(1)
people
['li', 'zhang']
# 指定位置插入某个元素
people = ['li', 'mu', 'zhang']
people.insert(1, 'mei')
people
['li', 'mei', 'mu', 'zhang']
# 直接替换某个元素
people = ['li', 'mu', 'zhang']
people[0] = 'zhang'
people
['zhang', 'mu', 'zhang']
# 可以进行嵌套索引
people = ['li', ['mu','mei'], 'zhang']
people[1][1]
'mei'
元组 tuple 数据类型
- tuple 一旦初始化就无法改变,这里的改变是在说指向无法改变
- 也是有序存储
# 创建空元组
t = ()
t
()
# 单个元素的元组
t = (1,)
# 多个元素元组
t = (1, 2, 3)
t
(1, 2, 3)
字典 dict 类型
- 字典类型是一种
key-value键值对的形式存在 dict类型具有查找和插入速度很快和占用内存较多有点,而list类型正好相反- dict 的
key是不可变对象,value可变 - dict 是无序的
# 创建词典
my_dict = {
'li':12,
'wang':13,
'wu':35
}
my_dict
{'li': 12, 'wang': 13, 'wu': 35}
# 查找元素
my_dict['wu']
35
# 判断元素是否存在,不存在返回默认值
print(my_dict.get('wu', 23))
print(my_dict.get('lv', 18))
35
18
# 删除元素
my_dict.pop('wu')
my_dict
{'li': 12, 'wang': 13}
集合 set 类型
- set 是相当于存储一组 key 的结合,不存储 value
- key不可以重复
- 使用
set()包含一个list创建集合 - 使用
&和|可以对集合进行交集、并集运算
s1 = set([1, 3, 4, 4])
s2 = set([4, 5, 5, 4, 8])
s1 & s2
{4}
# 添加元素
s1.add(5)
s1
{1, 3, 4, 5}
# 移除元素
s2.remove(5)
s2
{4, 8}
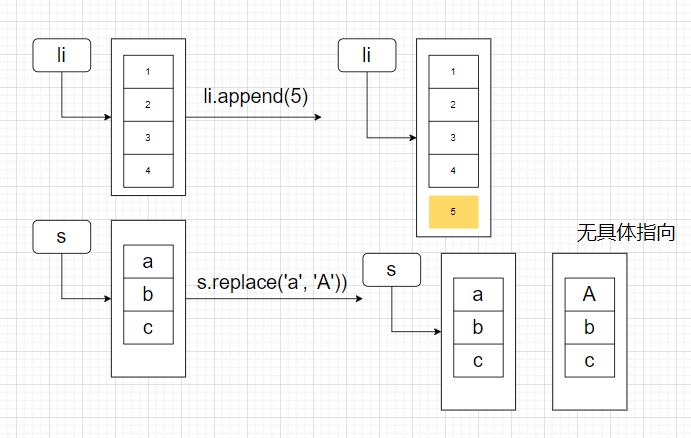
list是可变对象,当一个变量指向 list,操作会改变其值str是不可变对象,对其操作会生成一个新的存储空间,但不会覆盖原来的值
li = [1, 2, 3, 4]
li.append(5)
print(li)
s = 'abc'
s.replace('a', 'A')
print(s)
[1, 2, 3, 4, 5]
abc
条件和判断
- Python 使用
if、elif以及else作判断
# 顺序执行,只要满足其中一个添加就会退出
age = 5
if age <= 7:
print('child')
elif age <= 18:
print('teenager')
else:
print('adult')
child
- 使用
if x可以简写,x可以是非空数值、非空字符串、非空 list,都会判断为True
x = 1
if x:
print('True')
True
循环
- 使用
break打断循环,使用continue跳出本次循环 break和continue会造成循环逻辑分叉较多,尽量不要用
# for循环
sum = 0
for i in range(10):
sum += i
print(sum)
45
# while循环
sum = 0
n = 0
while n < 10: # 只要条件满足便会一直循环
sum += n
n += 1
print(sum)
45
函数
调用函数
- 可以直接使用 Python 内置的函数
- 直接
int(124.0)可以进行数据转换 - 当把函数名赋予一个变量的时候,相当于给这个函数给出了一个别名
a = abs
a(-19)
19
定义函数
- 定义函数时,需要确定函数名和参数个数
- 如果有必要,可以先对参数的数据类型做检查
- 函数执行完毕也没有
return语句时,自动 returnNone - 函数可以同时返回多个值,但其实就是一个
tuple
# 函数传入参数的类型检查,使用raise抛出一个错误
def my_abs(x):
if not isinstance(x, (int, float)):
raise(TypeError('bad operand type'))
if x >= 0:
return x
else:
return -x
my_abs('f')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [90], in <cell line: 9>()
7 else:
8 return -x
----> 9 my_abs('f')
Input In [90], in my_abs(x)
2 def my_abs(x):
3 if not isinstance(x, (int, float)):
----> 4 raise(TypeError('bad operand type'))
5 if x >= 0:
6 return x
TypeError: bad operand type
# 返回多个值
def f1(a, b):
return a+b, a-b
x, y = f1(2, 3)
print(f'{x} {y}')
5 -1
函数参数
必选参数
def add(a, b):
return a+b
add(2,3)
5
默认参数
- 必选参数在前,默认参数在后
- 变化大的参数在前,变化小的在后
- 默认参数必须指向不可变对象,可变的包含元组和列表
def add(a, b=1):
return a+b
add(2, 4)
6
可变参数
- 传入参数可变,可以为
0个或者1个 - 在函数定义部分添加
*,内部接受到的是一个tuple - 如果已经有一个
list或者tuple,可以在调用函数时候给参数前加*
# 函数内部接受到的是一个 tuple
def calc(*numbers):
sum = 0
for n in numbers:
sum += n
return sum
calc(2,2,4,4,5)
17
# 如果已经有一个list或tuple
t = tuple([1,2,4,5])
calc(*t)
12
关键字参数
- 关键字参数允许传入
0个或者任意个包含参数名的参数 - 这些关键字参数自动组成一个
dict - 使用场景:强制填写必要的信息,但可以接受额外信息
## 定义关键字参数,多余的会组成一个字典输出
def person(name, age, **kw):
print(f'name: {name} age: {age} other: {kw}')
person('Bob', 23, city = 'beijing', gender = 'M')
name: Bob age: 23 other: {'city': 'beijing', 'gender': 'M'}
## 调用已经构建好的字典
extra = {'name':'Bob',
'age':23,
'city':'Beijing',
'gender':'M'}
person(**extra)
name: Bob age: 23 other: {'city': 'Beijing', 'gender': 'M'}
命名关键字参数
- 函数无可变参数时候,使用
*与命名关键字参数分隔 - 函数有可变参数时候,调用保证命名关键字参数的传入
# 使用*分隔之后的命名关键字参数
def person(name, age, *, city, job):
print(name, age, city, job)
person('Jack', 24, city='beijing', job='Engineer')
Jack 24 beijing Engineer
# 如果函数定义有可变参数
def person(name, age, *args, city='Beijing', job):
print(name, age, args, city, job)
person('Jack', 24, job='Engineer')
Jack 24 () Beijing Engineer
函数组合
- Python 函数按照顺序必选、默认、可变、关键字以及命名关键字参数,可以组合使用
- 不要同时使用太多组合,否则函数接口的理解行会降低
*args是可变参数,接收的是一个tuple**kw是关键字参数,接受的是一个dict
# 包含可变参数
def f1(a, b, c=0, *args, **kw,):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
# 不包含可变参数
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
f1(1, 2, 3, 'a', 'b', city=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'city': 99}
f2(1, 2, 4, d=99, ext=None)
a = 1 b = 2 c = 4 d = 99 kw = {'ext': None}
# 可以直接组成tuple进行输出
args = (1, 2, 3, 4)
kw = {'d': 99, 'x': '#'}
f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
递归函数
- 使用递归函数优点是逻辑简单清晰,缺点是可能导致栈溢出
- 可以通过尾递归优化防止栈溢出,尾递归是指,在函数返回的时候,调用自身本身,并且,return 语句不能包含表达式
Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题
# 简单递归函数
def fact(n):
if n == 1:
return 1
else:
return n*fact(n-1)
fact(10)
3628800
# 尾递归优化
def fact(n):
return fact_iter(n, 1)
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)
fact(10)
3628800
函数高级特性
- 这一部分主要用来简化 Python 书写
切片
- 字符串、列表以及元组都可以进行切片操作
- 最后一个元素索引为
-1
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
L[0:1]
['Michael']
L[:] # 开辟存储空间,复制列表L
['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
L[0:4:2]
['Michael', 'Tracy']
迭代
- Python 中的字符串、列表、元组和字典都可以进行迭代
- 使用
Iterable判断是否是可迭代对象 dict默认迭代key,使用d.values()迭代值,d.items()同时迭代key和value
# 判断字符串对象是否是迭代对象
from collections.abc import Iterable
isinstance('abc', Iterable)
True
列表生成式
- 使用列表生成式可以生成简洁的代码
- 注意包含条件选择的列表生成式
# 筛选偶数
[x for x in range(1, 11) if x % 2 == 0]
[2, 4, 6, 8, 10]
# 包含if...else...的列表生成式
[x if x % 2 == 0 else -x for x in range(1, 11)]
[-1, 2, -3, 4, -5, 6, -7, 8, -9, 10]
生成器
- 可以简单通过将列表的
[]替换为()创建一个generator generator保存的是算法,可以选取固定元素- 调用
generator函数会创建一个generator对象,多次调用generator函数会创建多个相互独立的generator,正确写法是创建一个generator对象多次调用 - 普通函数在执行的时候遇到
return语句或者最后一行语句返回,而generator是从yield语句处继续执行 - 执行完毕若继续循环输出会返回一个
StopIteration错误
# 创建给生成器
f = (x for x in range(10))
# next(f)
# 使用循环对生成器进行输出
for n in f:
print(n)
0
1
2
3
4
5
6
7
8
9
# 斐波那契数列普通函数
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
fib(5)
1
1
2
3
5
'done'
# 斐波那契数列迭代器方式书写
def g_fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
f = g_fib(6)
for n in f:
print(n)
1
1
2
3
5
8
迭代器
- 可用于
for循环的数据类型- generator 类型,包含生成器和带 yield 的 generator function
- 集合数据类型,如 list、tuple、dict、set、str
- 凡是可作用于
for循环的对象都是Iterable类型 - 凡是可作用与
next()都是Iterator类型,表示一个惰性计算的序列 - 使用
iter()函数可以将Iterable变为Iterator Python的for循环本质上就是通过不断调用next()函数实现的
for x in [1, 2, 3, 4, 5]:
pass
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
函数式编程
- 函数式编程特点就是允许把函数本身作为一个参数传入另一个函数,还允许返回一个函数
高阶函数
- 将函数作为参数进行传入的成为高阶函数
- 函数名本身就是一个变量,而函数可以接受变量
# 函数名作为变量
f = abs
f(-1)
1
# 一个简单的高阶函数
def add(a, b, f):
return f(a) + f(b)
add(-3, -4, abs)
7
map 函数
- 对于 map/reduce 的理解可以参考 Google 发表的的MapReduce: Simplified Data Processing on Large Clusters
map()函数接受两个参数,一个是函数,一个是Iterablemap将传入的函数依次作用到序列的每个元素,再将结果作为Iterator返回
# 一个简单的map函数运用
def f(x):
return x*x
li = map(f, [1, 2, 3, 4])
# Iterator是一个惰性序列,需要通过list()转为一个序列输出
list(li)
[1, 4, 9, 16]
# 一个int2str直观的例子
li = [1, 2, 3, 4, 5, 7]
new_li = map(str, li)
list(new_li)
['1', '2', '3', '4', '5', '7']
reduce 函数
reduce将函数作用在一个序列上,这个函数必须接收两个参数- 效果就是:$reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)$
from functools import reduce
# 一个对序列求和的简单例子
def add(a, b):
return a+b
reduce(add, [1, 3, 5, 7, 9])
25
# 组合map和reduce函数写一个str2int函数
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))
str2int('124')
124
filter 函数
- 类似
map()函数一样也是接收两个参数,根据返回值是true还是false决定是否保留 filter函数返回的也是也惰性序列,因此只有在返回 filter()结果的时候,才会真正筛选并每次返回一个筛出的元素
# 返回偶数序列
def even(n):
return n%2==0
li = [1, 3, 4, 5, 8]
r = filter(even, li)
list(r)
[4, 8]
def is_palindrome(n):
str_A = str(n)
str_B = str_A[::-1]
return str_A == str_B
if list(filter(is_palindrome, range(1, 200))) == [1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 55, 66, 77, 88, 99, 101, 111, 121, 131, 141, 151, 161, 171, 181, 191]:
print('测试成功!')
else:
print('测试失败!')
测试成功!
sorted 函数
Python内置的sorted()函数可以对list进行排序- 添加
key函数相当于将key函数作用在每个元素之上再进行比较,返回原始元素的排序 - 使用
reverse=True可以实现反向排序
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
# 按照名称排序
def by_name(t):
return str.lower(t[0])
L2 = sorted(L, key=by_name)
print(L2)
[('Adam', 92), ('Bart', 66), ('Bob', 75), ('Lisa', 88)]
# 按照成绩排序
def by_score(t):
return -t[1]
L2 = sorted(L, key=by_score)
print(L2)
[('Adam', 92), ('Lisa', 88), ('Bob', 75), ('Bart', 66)]
返回函数
- 一个函数可以返回一个计算结果,也可以返回函数
- **闭包(Closure)**在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用,这样就构成了一个闭包
- 可以在内部函数添加
nonlocal声明,解释器便会将外部函数变量看作内函数的局部变量
# 一个简单的例子
# 每次调用都会返回一个新的函数,f1()和f2()调用结果互不影响
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f = lazy_sum(1, 2, 3)
f()
6
# 仅读取x的值:
def inc():
x = 0
def fn():
return x + 1
return fn
f = inc()
print(f())
1
def inc():
x = 0
def fn():
nonlocal x # 使得x为内函数局部变量
x = x + 1
return x
return fn
f = inc()
print(f())
1
匿名函数
Python中使用关键字lambda定义匿名函数,其只能有一个表达式,不用写return- 匿名函数可以赋值给一个变量,在通过利用变量调用该函数
- 匿名函数也可以作为返回值返回
# 之前对map函数的利用
list(map(lambda x: x*x, [1,2,4,5]))
[1, 4, 16, 25]
# 可以赋值给一个变量
f = lambda x: x*x
f(5)
25
# 作为一个函数返回
def build(x, y):
return lambda: x * x + y * y
build(2,3)
<function __main__.build.<locals>.<lambda>()>
装饰器
- 代码运行期间能动态增加功能的方式,称之为装饰器
decorator可以增强函数的功能,定义起来虽然有点复杂,但使用起来非常灵活和方便
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
now()
# 当我们打印now函数的名称时候发现已经改变,因此需要修改这种写法
print(now.__name__)
call now():
2015-3-25
wrapper
import functools
def log(func):
@functools.wraps(func) # 添加本行语句保持now函数属性未发生修改
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
now()
print(now.__name__)
call now():
2015-3-25
now
偏函数
- 使用 functools.parti`将函数的某些参数固定,返回一个新函数,使得调用更加简单
# 固定int()函数中base=2这个关键字参数
in2 = functools.partial(int, base=2)
in2('10')
2
# 将10作为*args输入参数左边
max2 = functools.partial(max, 10)
max2(1,2,3)
10
模块
- 将函数分组存放并设置相互调用构成的文件称之为模块
- 相同名称的函数和变量可以分别存在在不同模块
- 每一个模块文件夹内都需要有一个
__init__.py文件,可以有多级目录,如下
mycompany
├── web
│ ├── init.py
│ ├── www.py
│ └── utils.py
├── init.py
├── abc.py
└── utils.py
创建自定义模块
- 创建自定义模块命名为
hello.py如下所示,使用__xxx__和_xxx是特殊变量,属于 private 变量 - 添加
__name__=='__main__'是为了保证当次文件被import时不执行main部分,而确保main部分只在测试的时候执行
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
""" add some comments """
__author__ = 'Michael Liao'
import sys
def hello(name='tsh'):
print(sys.path)
print('hello %s' %name)
if __name__=='__main__':
hello()
['/home/jupyter_code', '/home/miniconda3/envs/py39/lib/python39.zip', '/home/miniconda3/envs/py39/lib/python3.9', '/home/miniconda3/envs/py39/lib/python3.9/lib-dynload', '', '/home/miniconda3/envs/py39/lib/python3.9/site-packages']
hello tsh
模块加载路径
- 当使用
import module时候Python解释器会在对应路径去搜寻有无对应模块 - 搜索路径存放在
sys下的path中 - 添加自己搜索目录可以修改
sys.path或者设置环境变量PATHONPATH
# 打印安装包路径
import sys
sys.path
['/home/jupyter_code',
'/home/miniconda3/envs/py39/lib/python39.zip',
'/home/miniconda3/envs/py39/lib/python3.9',
'/home/miniconda3/envs/py39/lib/python3.9/lib-dynload',
'',
'/home/miniconda3/envs/py39/lib/python3.9/site-packages']
- 直接修改 sys.path
import sys
sys.path.append(‘module path’) - 设置环境变量 PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置 Path 环境变量类似。注意只需要添加你自己的搜索路径,Python 自己本身的搜索路径不受影响。
面向对象编程
类和实例
- 两个重要概念类 class以及实例 instance
- 使用
class创建对象模板,定义属性和方法 - 定义的方法可以直接访问实例数据
Python允许对实例绑定任何数据
## 定义一个类
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def get_grade(self, score):
if score > 90:
return 'a'
else:
return 'b'
xiaomei = Student("xiaomei", 18)
print(xiaomei.age)
print(xiaomei.get_grade(85))
xiaomei.sex = 'female' # 添加动态属性
print(xiaomei.sex)
18
b
female
## Python3已经默认继承了object对象
class Student(object):
"""不添加object"""
name = "tsh"
class Person():
"""添加object"""
name = "yyy"
if __name__ == '__main__':
x = Student()
print(dir(x))
y = Person()
print(dir(y))
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name']
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name']
访问限制
- 通过给类内属性添加双下划线
__可以使得类属性只有内部可以访问 - 通过添加获取属性方法和修改属性方法完成对实例属性的修改
- 可以通过
_Student__name访问类内属性**(不建议这么做)**
## 定义一个类
class Student:
def __init__(self, name, age):
self.__name = name
self.age = age
xiaomei = Student("xiaomei", 18)
print(xiaomei._Student__name)
xiaomei
class Student:
def __init__(self, name, gender):
self.name = name
self.__gender = gender
def get_gender(self):
return self.__gender
def set_gender(self, new_gender):
self.__gender = new_gender
# 测试:
bart = Student('Bart', 'male')
if bart.get_gender() != 'male':
print('测试失败!')
else:
bart.set_gender('female')
if bart.get_gender() != 'female':
print('测试失败!')
else:
print('测试成功!')
测试成功!
继承和多态
- 通过继承子类可以获取父类的全部功能,但是子类的功能也可以进行修改
- 多态理解:当我们想对它父类下的多个子类进行操作的时候,由于子类继承了父类的一部分功能,因此可以直接针对父类进行函数功能的设计,再后期实现传入所有子类
class Animal:
def run(slef):
print("animal is running")
class Dog(Animal): # Dog类继承Animal类,没有run方法(默认添加了run方法)
pass
class Cat(Animal): # Cat类继承Animal类,有run方法
def run(slef):
print("cat is running")
class Car(object): # Car类没有继承Animal类,有run方法
def run(slef):
print("Car is running")
class Stone(object):
pass
def run_twice(animal): # Stone类没有继承Animal类,没有run方法
animal.run()
animal.run()
run_twice(Animal())
run_twice(Dog())
run_twice(Cat())
run_twice(Car())
run_twice(Stone())
animal is running
animal is running
animal is running
animal is running
cat is running
cat is running
Car is running
Car is running
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [304], in <cell line: 27>()
25 run_twice(Cat())
26 run_twice(Car())
---> 27 run_twice(Stone())
Input In [304], in run_twice(animal)
19 def run_twice(animal): # Stone类没有继承Animal类,没有run方法
---> 20 animal.run()
21 animal.run()
AttributeError: 'Stone' object has no attribute 'run'
cat = Cat()
print(isinstance(cat, Cat)) # 判断一个变量是否属于某一个类型
print(isinstance(cat, Animal)) # cat这个实例既属于Cat类,有属于Animal类
True
True
获取对象信息
- 使用 type()函数判断,返回的是对应的 ClassL 类型
type(123) # 判断基本类型和
int
type('abc') == type(123)
False
## 判断一个函数是否是函数
import types
def fn():
pass
print(type(fn)==types.FunctionType)
print(type(abs)==types.BuiltinFunctionType)
print(type(lambda x: x)==types.LambdaType)
print(type((x for x in range(10)))==types.GeneratorType)
True
True
True
True
- 使用 type()判断的都能用使用 isinstance()判断
isinstance(cat, Animal)
True
isinstance([1, 2, 3], (list, tuple)) # 判断视list还是tuple
True
- 使用 dir()
## 获得str对象的所有属性和方法
print(dir('123'))
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
len('123') == '123'.__len__()
True
# 让自己的类存在len(object)方法
class MyDog(object):
def __len__(self):
return 100
dog = MyDog()
len(dog)
100
- 配合 getattr()、setattr()以及 hasattr()可以直接操作一个对象状态
class MyObject(object):
def __init__(self):
self.x = 9
def power(self):
return self.x * self.x
obj = MyObject()
print(hasattr(obj, 'x')) # 有属性'x'吗?
print(setattr(obj, 'y', 19)) # 设置'y'属性为19
print(getattr(obj, 'y')) # 获取y属性
print(getattr(obj, 'z', 404)) # z属性不存在返回默认值得404
True
None
19
404
print(dir(obj))
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'power', 'x', 'y']
实例属性和类属性
从下面的例子可以看出,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性
# 直接定义类的属性
class Student:
name = 'Student'
s = Student()
print(s.name) # 打印name属性,因为实例并没有name属性,所以会继续查找class的name属性
print(Student.name) # 打印类的name属性
s.name = 'Michael' # 给实例绑定name属性
print(s.name) # 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的name属性
print(Student.name) # 但是类属性并未消失,用Student.name仍然可以访问
del s.name # 如果删除实例的name属性
print(s.name) # 再次调用s.name,由于实例的name属性没有找到,类的name属性就显示出来了
Student
Student
Michael
Student
Student
面向对象高级编程
使用slots
- 实例绑定的方法对另一个实例是不起作用的,只有与类直接绑定
- 使用
__slots__可以对实例的属性添加限制 __slots__定义的属性仅对当前的实例起作用,对继承子类不起作用
# 创建一个实例
class Student():
pass
s = Student()
# 给实例绑定一个属性
s.name = 'Bob'
# 给实例添加一个方法
def set_age(self, age):
self.age = age
from types import MethodType
s.set_age = MethodType(set_age, s)
s.set_age(25)
s.age
25
# 使用__slots__限制属性
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
s = Student()
s.score = 99
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Input In [319], in <cell line: 6>()
3 __slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
5 s = Student()
----> 6 s.score = 99
AttributeError: 'Student' object has no attribute 'score'
使用@property
- 在绑定属性中,如果直接把属性暴露出去,无法对参数进行检查
Python内置的@property负责把一个方法变成属性调用- 当不添加
setter方法的时候,定义的属性就是一个只读属性 - 要特别注意:属性的方法名不要和实例变量重名
# 一般类添加属性
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
# 带有@property的类
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
# Python练习的一个例子
class Screen(object):
@property
def width(self):
return self.__width
@width.setter
def width(self, value):
self.__width = value
@property
def height(self):
return self.__height
@height.setter
def height(self, value):
self.__height = value
@property
def resolution(self):
return self.width*self.height
# 测试:
s = Screen()
s.width = 1024
s.height = 768
print('resolution =', s.resolution)
if s.resolution == 786432:
print('测试通过!')
else:
print('测试失败!')
resolution = 786432
测试通过!
多重继承
- 通过多重集成,一个子类就可以获得多个父类的所有功能
- 在设计继承关系的过程中,主线都是单一继承下来的,可以同时混入多个类,利用
MixIn实现多继承 - 只允许单一继承的语言(如 Java)不能使用 MixIn 的设计
# 定义一些类
class Animal(object):
pass
# 大类:
class Mammal(Animal):
pass
class Bird(Animal):
pass
# 各种动物:
class Dog(Mammal):
pass
class Bat(Mammal):
pass
class Parrot(Bird):
pass
class Ostrich(Bird):
pass
# 定义更小的类
class RunnableMixIn(object):
def run(self):
print('Running...')
class FlyableMixIn(object):
def fly(self):
print('Flying...')
class Dog(Mammal, RunnableMixIn):
pass
定制类
Python中的class允许定义许多定制方法,可以十分方便生成特定的类- 更多定制方法可以参考Python 官方文档
__call__()还可以定义参数,这就使得创建的对象和函数的边界十分模糊,因此我们可以用callable()函数判断一个对象是否能被调用
# 定义__str__方法,可以返回包含实例属性的字符串
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name=%s)' % self.name
__repr__ = __str__ # 确保不使用print也可以使用
s = Student('Michael')
s
Student object (name=Michael)
# 添加__iter__方法返回一个可迭代对象
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 10: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
for n in Fib():
print(n)
1
1
2
3
5
8
# 添加__getitem__方法,确保可以类似list一样索引
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
f = Fib()
f[3]
3
# 添加__getattr__方法,返回不存在的属性值
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25
raise AttributeError('\'Student\' object has no attribute \'%s\'' % attr)
s = Student()
s.age()
25
# 添加__call__,调用实例自身方法
class Student():
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
s = Student('Bob')
s()
My name is Bob.
使用枚举类
- 可以通过大写变量来定义整数常量,优点是简单,缺点就是只有
int类型,仍是变量 Enum可以把一组相关常量定义在一个class中,且class不可变,成员可以直接比较- 使用
Enum提供模块,它定义了一个class类型,每个常量都是class的唯一实例
# 使用Enum来实现枚举常量功能
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May',
'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
for name, member in Month.__members__.items():
print(name, '=>', member, ',', member.value)
Jan => Month.Jan , 1
Feb => Month.Feb , 2
Mar => Month.Mar , 3
Apr => Month.Apr , 4
May => Month.May , 5
Jun => Month.Jun , 6
Jul => Month.Jul , 7
Aug => Month.Aug , 8
Sep => Month.Sep , 9
Oct => Month.Oct , 10
Nov => Month.Nov , 11
Dec => Month.Dec , 12
# 从Enum自定义类,@unique装饰器可以帮助我们检查保证没有重复值
from enum import Enum, unique
@unique
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
# 访问自定义枚举类型
Weekday.Tue.value
2
Weekday.Mon
<Weekday.Mon: 1>
Weekday['Mon']
<Weekday.Mon: 1>
Weekday(1).name
'Mon'
使用元类
- 使用
type()可以动态创建一个类,第一个参数是class名称,第二个参数是所要继承的类,第三个是class方法与函数的绑定 - 使用
Metaclass创建元类,可以把类看成是metaclass创建出来的实例 - 先定义
metaclass,就可以创建类,最后创建实例
# 使用type()动态创建一个类
def fn(self, name='world'):
print('HELLO, %s ' %name)
Hello = type('Hello', (object,), dict(hello=fn))
h = Hello()
h.hello()
HELLO, world
错误、处理和测试
- 常见错误类型
- 程序编写过程中造成的错误称为 BUG
- 用户输入造成的错误
- 无法在程序运行过程中预测的错误,例如:磁盘爆满或是网络掉线等
- 调试:跟踪程序执行,查看变量值的过程
- 测试:编写案例对程序进行测试也很重要
- 点击查看Python 内置错误类型及其集成关系
错误处理
内置错误捕获
try: # 先执行try部分
print('try...')
r = 10 / int('a')
print('result:', r)
except ValueError as e: # 多个except捕获不同错误类型,不写明类型的时候默认所有
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
else: # 没有错误的时候执行这一部分
print('no errors')
finally: # 这部分始终被执行
print('finally...')
print('END')
try...
ValueError: invalid literal for int() with base 10: 'a'
finally...
END
# UnicodeError是ValueError的一个子类,因此第二个except很难捕获到
def foo(s):
return 10 / int(s)
try:
foo('a')
except ValueError as e:
print('ValueError')
except UnicodeError as e:
print('UnicodeError')
ValueError
调用栈
- 如果错误没有被捕获到,Python 解释器会一直往上抛,直到程序退出
- 我们要根据抛出的错误信息,定位错误位置

记录错误
- 同样是出错,但程序打印完错误信息后会继续执行,并正常退出
logging还可以把错误记录到日志文件,方便事后排查
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()
print('END')
ERROR:root:division by zero
Traceback (most recent call last):
File "/tmp/ipykernel_31646/1371240815.py", line 11, in main
bar('0')
File "/tmp/ipykernel_31646/1371240815.py", line 7, in bar
return foo(s) * 2
File "/tmp/ipykernel_31646/1371240815.py", line 4, in foo
return 10 / int(s)
ZeroDivisionError: division by zero
END
抛出错误
- 一个错误也是
class类型,因此可根据继承关系自定义错误 - 建议尽量使用
Python内置错误类型
# 自定义错误类型
class FooError(ValueError):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s)
return 10 / n
foo('0')
---------------------------------------------------------------------------
FooError Traceback (most recent call last)
Input In [410], in <cell line: 11>()
8 raise FooError('invalid value: %s' % s)
9 return 10 / n
---> 11 foo('0')
Input In [410], in foo(s)
6 n = int(s)
7 if n==0:
----> 8 raise FooError('invalid value: %s' % s)
9 return 10 / n
FooError: invalid value: 0
"""
在这里,程序先捕捉到自定错误ValueError,但在bar()中又抛出这个错误,这里捕获这个错误的目的
只是记录一下错误,便于后续追踪,由于当前函数不知道如何处理此类错误,所以又将这个错误抛出到
当前,所以,最恰当的方式是继续往上抛,让顶层调用者去处理
"""
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise
bar()
ValueError!
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [419], in <cell line: 19>()
16 print('ValueError!')
17 raise
---> 19 bar()
Input In [419], in bar()
12 def bar():
13 try:
---> 14 foo('0')
15 except ValueError as e:
16 print('ValueError!')
Input In [419], in foo(s)
7 n = int(s)
8 if n==0:
----> 9 raise ValueError('invalid value: %s' % s)
10 return 10 / n
ValueError: invalid value: 0
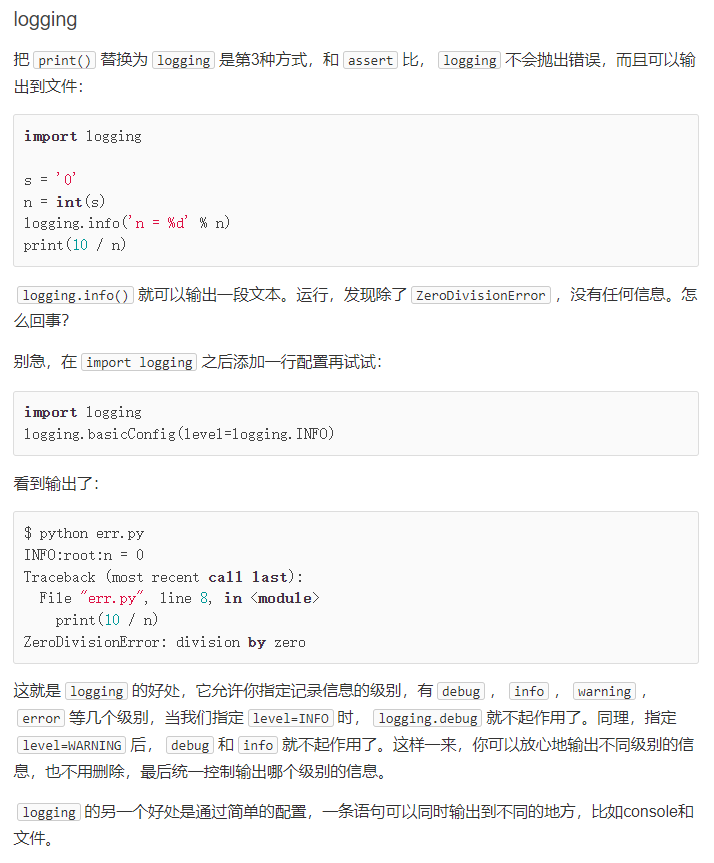
调试
- 使用
print()把有问题的变量打印出来观察 - 使用用断言
assert(),在这类可以通过运行python -O err.py可以关闭assert(这里命令注意是英文大写字母 O) - 使用
logging模块(比较推荐)
## 当表达式n!=0为false时候,后面代码抛出AssertionError: n is zero!
## 使用Python -0 err.py可以关闭assert
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')
main()
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Input In [420], in <cell line: 10>()
8 def main():
9 foo('0')
---> 10 main()
Input In [420], in main()
8 def main():
----> 9 foo('0')
Input In [420], in foo(s)
3 def foo(s):
4 n = int(s)
----> 5 assert n != 0, 'n is zero!'
6 return 10 / n
AssertionError: n is zero!
import logging
logging.basicConfig(level=logging.error)
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
C:\Users\SHAOHA~1\AppData\Local\Temp/ipykernel_26832/2604544736.py in <module>
5 n = int(s)
6 logging.info('n = %d' % n)
----> 7 print(10 / n)
ZeroDivisionError: division by zero
单元测试
- 单元测试是用来对一个模块、一个函数或者一个类来进行正确性检验的测试工作
- 单元测试不通过,程序不一定没 Bug,不通过则必定有 Bug
- 单元测试的测试用例要覆盖常用的输入组合、边界条件和异常
# 定义一个dict类
class Dict(dict):
def __init__(self, **kw):
super().__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Dict' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
- 编写单元测试时,我们需要编写一个测试类,从
unittest.TestCase继承 - 以
test开头的方法就是测试方法,不以test开头的不是,测试的时候不会被执行 - 对每一类测试都需要编写一个
test_xxx()方法 - 最常用的断言是
assertEqual() - 运行单元测试常见有两种方法
- 使用
setUp()和tearDown(),这两个方法会在分别调用每个测试方法时执行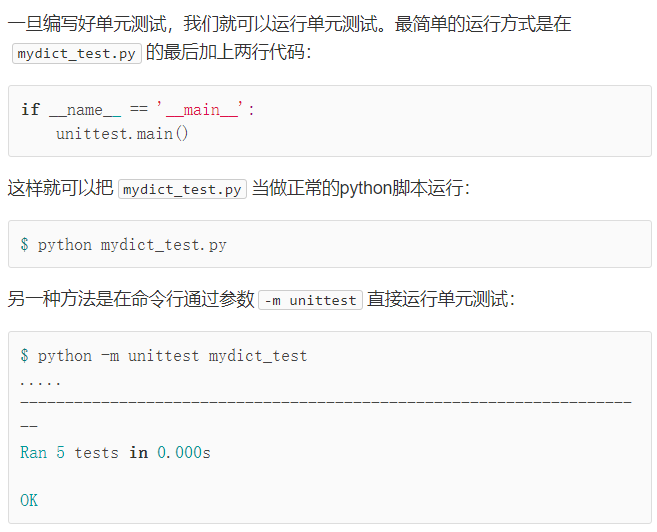
# 引入Python自带的unittest模块测试
import unittest
# from mydict import Dict
class TestDict(unittest.TestCase):
def test_init(self):
d = Dict(a=1, b='test')
self.assertEqual(d.a, 1)
self.assertEqual(d.b, 'test')
self.assertTrue(isinstance(d, dict))
def test_key(self):
d = Dict()
d['key'] = 'value'
self.assertEqual(d.key, 'value')
def test_attr(self):
d = Dict()
d.key = 'value'
self.assertTrue('key' in d)
self.assertEqual(d['key'], 'value')
def test_keyerror(self):
d = Dict()
with self.assertRaises(KeyError):
value = d['empty']
def test_attrerror(self):
d = Dict()
with self.assertRaises(AttributeError):
value = d.empty
文档测试
Python中的文档测试(doctest)模块可以直接提取注释中的代码并执行测试doctest严格按照Python交互式命令行的输入和输出来判断测试结果是否正确。只有测试异常的时候,可以用…表示中间一大段烦人的输出- 通过添加下列单元格中的最后三行,可以保证这个模块在被导入的时候不执行
main部分
本段程序保存为 dict.py 文件,整个程序的运行使用 python dict.py
class Dict(dict): ’’' Simple dict but also support access as x.y style.
>>> d1 = Dict()
>>> d1['x'] = 100
>>> d1.x
100
>>> d1.y = 200
>>> d1['y']
200
>>> d2 = Dict(a=1, b=2, c='3')
>>> d2.c
'3'
>>> d2['empty']
Traceback (most recent call last):
...
KeyError: 'empty'
>>> d2.empty
Traceback (most recent call last):
...
AttributeError: 'Dict' object has no attribute 'empty'
'''
def __init__(self, **kw):
super(Dict, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Dict' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
if name==’main’: import doctest doctest.testmod()
IO 编程
- 由于数据是在内存中驻留,这里的
IO指的是数据的输入和输出 - 由于 CPU 和内存的速度远远高于外设,所以在
IO编程中存在同步和异步问题,两者的区别在于是否等待IO执行的结果 - 异步效率高,编程模型复杂,同步则相反
文件读写
读文件
- Python 内置了 open()函数用于读写文件,默认
UTF-8编码的文本文件,读取方法可分为:- 文件很小,一次性读取
read()最方便 - 不确定文件大小,反复调用
read(size)比较可靠 - 如果是配置文件,调用
readlines()一次性读取所有内容并返回list最方便
- 文件很小,一次性读取
- 读取二进制文件如视频、图片等可以以
'rb'模式打开 - 文件采用其他编码,可以给
open函数传入encoding='gbk'等参数 - 遇到
UnicodeDecodeError,因为在文本文件中可能夹杂了非法编码的字符。遇到这种情况,open()函数还接收一个errors='ignore'参数,表示忽略
# 一次性读取
with open('test_IO.txt', 'r') as f:
print(f.read())
123
456
ABC
# 每次读取两个字节
with open('test_IO.txt', 'r') as f:
for n in range(10):
print(f.read(2))
12
3
45
6
AB
C
# 逐行读取
with open('test_IO.txt', 'r') as f:
for line in f.readlines():
print(line.strip()) # 把末尾的'\n'删掉
123
456
ABC
写文件
- 使用’w’或’wb’写入文本或者二进制文件,‘a’可以追加模式写入
with open('test_IO.txt', 'a') as f:
f.write('Hello, world!') # 主要原文件文件最后一行是否换行
StringIO 和 BytesIO
- 实现对内存中 str 和二进制数据的读写
# 在内存中初始化f,并使用文件类似操作进行读取
from io import StringIO
f = StringIO('hello,\nworld')
while True:
s = f.readline()
if s == '':
break
print(s.strip())
hello,
world
# 内存中写入BytestIO
from io import BytesIO
f = BytesIO()
f.write('中文'.encode('utf-8'))
print(f.getvalue())
b'\xe4\xb8\xad\xe6\x96\x87'
# 初始化二进制数据流,并读取
f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
f.read()
b'\xe4\xb8\xad\xe6\x96\x87'
操作文件和目录
- 通过使用
os模块我们可以对文件和目录等进行操作 os.name结果为nt则为windows系统,非windows系统可以用os.uname()获取更详细信息os.environ可以获取所有环境变量,os.environ.get('key')可以获取某个环境变量的值,例如'path'- 利用
os和os.path对目录和文件进行操作 - 对路径进行拼接或分割时,不要直接操作字符串,可以通过
os.path.join()函数和os.path.split()函数进行操作 shutil模块提供了copyfile()可以看作是对os模块的补充
# 查看当前目录的绝对路径
os.path.abspath('.')
'/home/jupyter_code'
# 创建一个test目录
os.mkdir('/home/jupyter_code/testdir')
# 删除一个目录
os.rmdir('/home/jupyter_code/testdir')
# 拼接路径
os.path.join('/home/jupyter_code','testdier')
'/home/jupyter_code/testdier'
# 拆分路径
os.path.split('/home/jupyter_code/maren.ipynb')
('/home/jupyter_code', 'maren.ipynb')
# 拆分拓展名
os.path.splitext('/home/jupyter_code/maren.ipynb')
('/home/jupyter_code/maren', '.ipynb')
# 列出所有目录
[x for x in os.listdir('.') if os.path.isdir(x)]
['WZRY', '.ipynb_checkpoints', 'Blog_draft', 'Wandb']
# 列出所有txt文件
[x for x in os.listdir('.') if os.path.splitext(x)[1] == '.txt']
['test_IO.txt']
序列化
- 将内存中的变量变为可存或传输的过程称为序列化
- 使用
pickle可以保存不是很重的数据,这是由于其只能用于Python并且不同的Python可以不兼容 - 对于比较重要的内存中的变量一般保存为
JSON格式,在各种语言之间比较通用 - 注意观察代码中
dumps和dump的区别 - 因为通常
class的实例都有一个__dict__属性,它就是一个dict,用来存储实例变量
d = {'name':'Vob',
'age':12,
'score':90}
import pickle
# 将变量d写入txt文件
with open('d.txt','wb') as f:
pickle.dump(d, f)
# 将变量从磁盘读入到内存
with open('d.txt', 'rb') as f:
pickle.load(f)
import json
# 使用json将序列化为字符串
my_dict = dict(name='tsh', age=24, job='student')
json.dumps(my_dict)
'{"name": "tsh", "age": 24, "job": "student"}'
# 将变量my_dict保存为json文件
with open('my_dict.json', 'w') as f:
json.dump(my_dict, f, indent=4)
# 将JSON文件保存为变量读入到内存中
with open('my_dict.json','r') as f:
data = json.load(f)
# 使用__dict__序列化实例
import json
class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
s = Student('Bob', 20, 88)
print(json.dumps(s, default=lambda obj: obj.__dict__))
{"name": "Bob", "age": 20, "score": 88}
# 反序列化实例
def dict2student(d):
return Student(d['name'], d['age'], d['score'])
json_str = '{"age": 20, "score": 88, "name": "Bob"}'
print(json.loads(json_str, object_hook=dict2student))
<__main__.Student object at 0x7f4e1133d730>
多进程与多线程
单个py文件执行一般都是单个进程,单个线程,要解决多任务实现方式:
- 多进程模式
- 多线程模式
- 多进程+多线程
多进程
- 操作系统自动把当前进程(称为父进程)复制了一份(称为子进程)
Unix/Linux提供fork()系统调用- 要实现跨平台的多进程,可以使用
multiprocessing模块 - 可以使用
Pool启动大量子进程 - 进程间通信是通过
Queue、Pipes等实现的 import os
print(‘Process (%s) start…’ % os.getpid())
Only works on Unix/Linux/Mac:
pid = os.fork() print(’*’*10) if pid == 0: print(‘I am child process (%s) and my parent is %s.’ % (os.getpid(), os.getppid())) else: print(‘I (%s) just created a child process (%s).’ % (os.getpid(), pid))
“““outputs Process (31646) start…
I (31646) just created a child process (12118).
I am child process (12118) and my parent is 31646. "””
# 下面的例子演示了启动一个子进程并等待其结束
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join() # 等待子进程结束后再继续往下运行,通常用于进程间的同步
print('Child process end.')
Parent process 31646.
Child process will start.
Run child process test (12113)...
Child process end.
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close() # 调用close()之后就不能继续添加新的Process
print('hello')
p.join() # Pool对象调用join()方法会等待所有子进程执行完毕
print('All subprocesses done.')
Parent process 31646.
Waiting for all subprocesses done...
hello
Run task 2 (12821)...Run task 3 (12822)...Run task 0 (12819)...Run task 1 (12820)...
Task 2 runs 0.01 seconds.
Run task 4 (12821)…
Task 0 runs 0.83 seconds.
Task 3 runs 1.35 seconds.
Task 4 runs 1.30 seconds.
Task 1 runs 1.92 seconds.
All subprocesses done.
# Python代码中运行命令nslookup www.python.org,和命令行运行效果类似
import subprocess
print('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)
print(os.getpid())
$ nslookup www.python.org
Server: 100.100.2.136
Address: 100.100.2.136#53
Non-authoritative answer:
www.python.org canonical name = dualstack.python.map.fastly.net.
Name: dualstack.python.map.fastly.net
Address: 151.101.108.223
Name: dualstack.python.map.fastly.net
Address: 2a04:4e42:11::223
Exit code: 0
31646
# 带有子进程输入的可以使用communicate()方法
import subprocess
print('$ nslookup')
p = subprocess.Popen(['nslookup'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('utf-8'))
print('Exit code:', p.returncode)
$ nslookup
Server: 100.100.2.136
Address: 100.100.2.136#53
Non-authoritative answer:
python.org mail exchanger = 50 mail.python.org.
Authoritative answers can be found from:
Exit code: 0
# 实现进程之间的通信
# 以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
Process to write: 13074Process to read: 13075
Put A to queue...
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
多线程
- 多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦
基础知识
- 进程是由多个线程组成,一个进程至少有一个线程
- 线程是操作系统直接支持的执行单元,使用
threading高级模块实现多线程 - 启动一个线程就是把一个函数传入并创建
Thread实例,然后调用start()开始执行 Python进程默认会启动一个线程,该线程成为主线程,名称是MainThread,子线程名字在创建时候确定
# 一个简单多线程实例
import time, threading
def loop():
print('Thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('Thread %s ended' % threading.current_thread().name)
print('thread %s is running' % threading.current_thread().name)
t = threading.Thread(target=loop, name='ThreadLoop')
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
thread MainThread is running
Thread ThreadLoop is running...
thread ThreadLoop >>> 1
thread ThreadLoop >>> 2
thread ThreadLoop >>> 3
thread ThreadLoop >>> 4
thread ThreadLoop >>> 5
Thread ThreadLoop ended
thread MainThread ended.
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱。
锁的好处:
- 确保了某段关键代码只能由一个线程从头到尾完整地执行, 锁的坏处:
- 阻止多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降
- 其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止
可以添加threading.lock()给进程上锁,保证该只有进程执行在单独执行之后再执行其他
# 在这个实例中,理论结果应该为0,由于t1和t2交替执行,导致内容混乱
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(2000000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
-13
# 添加锁的多进程
import time, threading
# 假定这是你的银行存款:
balance = 0
lock = threading.Lock()
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
# def run_thread(n):
# for i in range(2000000):
# change_it(n)
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
0
import threading, multiprocessing
multiprocessing.cpu_count()
2
多核 CPU
Python 的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行 100 条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1 个核.
Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个 Python 进程有各自独立的 GIL 锁,互不影响。
ThreadLocal
- 使用
ThreadLocal解决了一个进程中各个参数互相传递的问题 ThreadLocal可以看作是构造了一个全局变量,但是它在每个进程中的相同属性有不同属性值
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# 绑定ThreadLocal的student:
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)
进程 vs 线程
- 要实现多任务,通常设计
Master-Worker模式,Master负责分配任务,Worker负责执行任务 - 多进程模式
- 稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程,(当然主进程挂了所有进程就全挂了,但是
Master进程只负责分配任务,挂掉的概率低) - 缺点是创建进程的代价大,在
Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
- 稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程,(当然主进程挂了所有进程就全挂了,但是
- 多线程模式
- 在
Windows下,多线程的效率比多进程要高 - 缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存
- 在
- 线程切换
- 虽然切换很快,但也需要消耗资源时间
- 多个任务一旦多到一定程度,就会消耗系统所有资源,导致效率急剧下降
- 任务类型
- 计算密集型任务:主要消耗 CPU 资源,因此,代码运行效率至关重要,最好用 C 语言写
- IO 密集型:涉及到网络、磁盘 IO 的任务都是 IO 密集型任务,这类任务的特点是 CPU 消耗很少,任务的大部分时间都在等待 IO 操作完成(因为 IO 的速度远远低于 CPU 和内存的速度),最合适的就是脚本语言
- 异步 IO:
- 现代操作系统对 IO 操作已经做了巨大的改进,如果充分利用操作系统提供的异步 IO 支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型
- 对应到
Python语言,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。
分布式进程
- Thread 和 Process优选 Process,因为
Process更加稳定,并且可以分布到多个机器,而 Thread 最多只能分布到同一台机器的多个 CPU - Python 中
multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上 - 详细实例可以查看分布式进程
正则表达式
- 正则表达式是对字符串处理的一种有力工具,关于正则表达式学习可以参考这里
- 由于 Python 字符串本身需要转义,在构造正则表达式的时候建议使用
r'str'方式 - Python 在使用正则表达式的过程中,首先编译正则表达式,再进行匹配,若一条正则表达式用很多次,可以用
re.compile(r're')提前定义 - 正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符,例如
\d+表示匹配至少一个数字,此时 Python 运行过程中将匹配更多数字,使用\d+?将转为非贪婪模式 - 使用
re.finditer生成一个可迭代对象,可以配合re.sub使用 - 使用
re.sub对匹配字符串进行替换
# 简单示例
import re
re.match(r'\d+', '12jlfj12')
<re.Match object; span=(0, 2), match='12'>
在进行匹配的过程中可以使用|符号选择多种正则表达模式:
re.I忽略大小写re.M多行匹配(匹配多行的^和$)re.S使得.匹配换行符在内的任意字符(正常模式中.不包括换行符)re.X为了增加可读性,忽略空格和 # 后面的注释
# 多次调用表达式示例
import re
# 构建编译正则表达式
pattern = re.compile(r'\d+')
# 使用match匹配,从头开始匹配,不符合正则表达式则直接返回None
print('using match functiong:')
m = pattern.match('f22one123twothereefour4') #从头匹配输出
print(m)
# 使用search匹配,全局匹配,返回第一个
print('using search functiong:')
m = pattern.match('123f22one123twothereefour4') #从头匹配输出
print(m)
# 使用findout匹配,返回符合正则表达式的所有子字符串列表
print('using findout functiong:')
m = pattern.findall('123f22one123twothereefour4') #从头匹配输出
print(m)
using match functiong:
None
using search functiong:
<re.Match object; span=(0, 3), match='123'>
using findout functiong:
['123', '22', '123', '4']
# 切分字符串实例
# 正常字符串切分实例(无法识别连续空格)
n_str = 'a b b c fsd fsd'.split(' ')
print(n_str)
# 正则表达式分割字符串(可以识别多个空格)
re_str = re.split(r'\s+', 'a b b c fsd fsd')
print(re_str)
['a', 'b', 'b', 'c', 'fsd', '', 'fsd']
['a', 'b', 'b', 'c', 'fsd', 'fsd']
# 对匹配项分组抽取
import re
pattern = re.compile(r'([a-z]+) ([a-z]+)',re.I|re.M)
m = pattern.match("Hello World Wide Web!")
print(m.groups()) # 返回整个匹配到的字符串
print(m.group(1)) # 返回第一个匹配项的第一个分组
('Hello', 'World')
Hello
import re
# 默认贪婪模式匹配
print(re.match('(\d+)(0*)$', '12300').groups())
# 非贪婪模式
print(re.match('(\d+?)(0*)$', '12300').groups())
('12300', '')
('123', '00')
# 生成一个可迭代对象
text = "He was carefully disguised but captured quickly by police."
for m in re.finditer(r"\w+ly\b", text):
print('%02d-%02d: %s' % (m.start(), m.end(), m.group(0)))
07-16: carefully
40-47: quickly
# 对匹配字符串进行替换
# Method 1:
r1 = re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam', flags=re.IGNORECASE)
print(r1)
# Method 2:
def dashrepl(matchobj): # 对匹配对象进行附加操作
if matchobj.group(0) == '-': return '+'
else: return '*'
r2 = re.sub('-{1,2}', dashrepl, 'pro----gram-files')
print(r2)
Baked Beans & Spam
pro**gram+files
电子邮件
- MUA:Mail User Agent——邮件用户代理
- MTA:Mail Transfer Agent——邮件传输代理
- MDA:Mail Delivery Agent——邮件投递代理
- 一封电子邮件的旅程:
发件人 -> MUA -> MTA -> MTA -> 若干个 MTA -> MDA <- MUA <- 收件人 - 发邮件时,MUA 和 MTA 使用的协议就是 SMTP:Simple Mail Transfer Protocol,后面的 MTA 到另一个 MTA 也是用 SMTP 协议。
- 收邮件时,MUA 和 MDA 使用的协议有两种:POP:Post Office Protocol,目前版本是 3,俗称 POP3;IMAP:Internet Message Access Protocol,目前版本是 4,优点是不但能取邮件,还可以直接操作 MDA 上存储的邮件,比如从收件箱移到垃圾箱,等等
协议 服务器 SSL 非 SSL
SMTP smtp.163.com 465 25
IMAP imap.163.com 993 143
POP3 pop.163.com 995 110
——————————-
SMTP smtp.qq.com 465/587
IMAP imap.qq.com 993
POP3 pop.qq.com 995
——————————-
SMTP smtp.gmail.com 465(SSL)/587(TLS/STARTTLS)
IMAP imap.gmail.com 993
POP3 pop.gmail.com 995
——————————-
163/qq: password 为授权码
gmail: password 为邮箱密码
SMTP 发送邮件
- Python 内置模快
smtplib(发送邮件)以及email(构造邮件)
简单示例
# 构造一个纯文本邮件
from email.mime.text import MIMEText
msg = MIMEText('hello, send by tsh', 'plain', 'utf-8')
# 通过SMTP发送
# 输入Email地址和口令
from_addr = '1185725270@qq.com'
password = 'ainiajweovxdhifc'
# 输入收件人地址
to_addr = 'xt_shaohan@163.com'
# 输入SMTP服务器地址
smtp_server = 'smtp.qq.com'
import smtplib
server = smtplib.SMTP(smtp_server, 25) # SMTP协议默认端口是25
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
send: 'ehlo [222.28.39.219]\r\n'
reply: b'250-newxmesmtplogicsvrszc8.qq.com\r\n'
reply: b'250-PIPELINING\r\n'
reply: b'250-SIZE 73400320\r\n'
reply: b'250-STARTTLS\r\n'
reply: b'250-AUTH LOGIN PLAIN XOAUTH XOAUTH2\r\n'
reply: b'250-AUTH=LOGIN\r\n'
reply: b'250-MAILCOMPRESS\r\n'
reply: b'250 8BITMIME\r\n'
reply: retcode (250); Msg: b'newxmesmtplogicsvrszc8.qq.com\nPIPELINING\nSIZE 73400320\nSTARTTLS\nAUTH LOGIN PLAIN XOAUTH XOAUTH2\nAUTH=LOGIN\nMAILCOMPRESS\n8BITMIME'
send: 'AUTH PLAIN ADExODU3MjUyNzBAcXEuY29tAGFpbmlhandlb3Z4ZGhpZmM=\r\n'
reply: b'235 Authentication successful\r\n'
reply: retcode (235); Msg: b'Authentication successful'
send: 'mail FROM:<1185725270@qq.com> size=125\r\n'
reply: b'250 OK\r\n'
reply: retcode (250); Msg: b'OK'
send: 'rcpt TO:<xt_shaohan@163.com>\r\n'
reply: b'250 OK\r\n'
reply: retcode (250); Msg: b'OK'
send: 'data\r\n'
reply: b'354 End data with <CR><LF>.<CR><LF>.\r\n'
reply: retcode (354); Msg: b'End data with <CR><LF>.<CR><LF>.'
data: (354, b'End data with <CR><LF>.<CR><LF>.')
send: b'Content-Type: text/plain; charset="utf-8"\r\nMIME-Version: 1.0\r\nContent-Transfer-Encoding: base64\r\n\r\naGVsbG8sIHNlbmQgYnkgdHNo\r\n.\r\n'
reply: b'250 OK: queued as.\r\n'
reply: retcode (250); Msg: b'OK: queued as.'
data: (250, b'OK: queued as.')
send: 'quit\r\n'
reply: b'221 Bye.\r\n'
reply: retcode (221); Msg: b'Bye.'
(221, b'Bye.')
完整示例
上一个邮件示例发送存在的问题
- 邮件没有主题
- 收件人的信息不友好
from email import encoders
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, 'utf-8').encode(), addr))
# 输入Email地址和口令
from_addr = '1185725270@qq.com'
password = 'ainiajweovxdhifc'
# 输入收件人地址
to_addr = 'shaohan.tian@hotmail.com'
# 输入SMTP服务器地址
smtp_server = 'smtp.qq.com'
# # 输入Email地址和口令
# from_addr = 'xt_shaohan@163.com'
# password = 'MGIUKTXPIYYPRGCR'
# # 输入收件人地址
# to_addr = 'shaohan.tian@hotmail.com'
# # 输入SMTP服务器地址
# smtp_server = 'smtp.163.com'
msg = MIMEText('hello, send by Python...this is seconda email', 'plain', 'utf-8')
msg['From'] = _format_addr('田少晗QQmail <%s>' % from_addr)
msg['To'] = _format_addr('田少晗 <%s>' % to_addr)
msg['Subject'] = Header('来自SMTP的问候……', 'utf-8').encode()
server = smtplib.SMTP(smtp_server, 587)
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, to_addr, msg.as_string())
server.quit()
send: 'ehlo [222.28.39.219]\r\n'
reply: b'250-newxmesmtplogicsvrszc10.qq.com\r\n'
reply: b'250-PIPELINING\r\n'
reply: b'250-SIZE 73400320\r\n'
reply: b'250-STARTTLS\r\n'
reply: b'250-AUTH LOGIN PLAIN XOAUTH XOAUTH2\r\n'
reply: b'250-AUTH=LOGIN\r\n'
reply: b'250-MAILCOMPRESS\r\n'
reply: b'250 8BITMIME\r\n'
reply: retcode (250); Msg: b'newxmesmtplogicsvrszc10.qq.com\nPIPELINING\nSIZE 73400320\nSTARTTLS\nAUTH LOGIN PLAIN XOAUTH XOAUTH2\nAUTH=LOGIN\nMAILCOMPRESS\n8BITMIME'
send: 'AUTH PLAIN ADExODU3MjUyNzBAcXEuY29tAGFpbmlhandlb3Z4ZGhpZmM=\r\n'
reply: b'235 Authentication successful\r\n'
reply: retcode (235); Msg: b'Authentication successful'
send: 'mail FROM:<1185725270@qq.com> size=337\r\n'
reply: b'250 OK\r\n'
reply: retcode (250); Msg: b'OK'
send: 'rcpt TO:<shaohan.tian@hotmail.com>\r\n'
reply: b'250 OK\r\n'
reply: retcode (250); Msg: b'OK'
send: 'data\r\n'
reply: b'354 End data with <CR><LF>.<CR><LF>.\r\n'
reply: retcode (354); Msg: b'End data with <CR><LF>.<CR><LF>.'
data: (354, b'End data with <CR><LF>.<CR><LF>.')
send: b'Content-Type: text/plain; charset="utf-8"\r\nMIME-Version: 1.0\r\nContent-Transfer-Encoding: base64\r\nFrom: =?utf-8?b?55Sw5bCR5pmXUVFtYWls?= <1185725270@qq.com>\r\nTo: =?utf-8?b?55Sw5bCR5pmX?= <shaohan.tian@hotmail.com>\r\nSubject: =?utf-8?b?5p2l6IeqU01UUOeahOmXruWAmeKApuKApg==?=\r\n\r\naGVsbG8sIHNlbmQgYnkgUHl0aG9uLi4udGhpcyBpcyBzZWNvbmRhIGVtYWls\r\n.\r\n'
reply: b'250 OK: queued as.\r\n'
reply: retcode (250); Msg: b'OK: queued as.'
data: (250, b'OK: queued as.')
send: 'quit\r\n'
reply: b'221 Bye.\r\n'
reply: retcode (221); Msg: b'Bye.'
(221, b'Bye.')
发送 HTML 邮件
msg = MIMEText('<html><body><h1>Hello</h1>' +
'<p>send by <a href="http://www.python.org">Python</a>...</p>' +
'</body></html>', 'html', 'utf-8')
发送附件
from email import encoders
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
from email.mime.multipart import MIMEMultipart, MIMEBase
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, 'utf-8').encode(), addr))
# 输入Email地址和口令
from_addr = '1185725270@qq.com'
password = 'ainiajweovxdhifc'
# 输入收件人地址
to_addr = 'xt_shaohan@163.com'
# 输入SMTP服务器地址
smtp_server = 'smtp.qq.com'
# 邮件对象:
msg = MIMEMultipart()
msg['From'] = _format_addr('Python爱好者 <%s>' % from_addr)
msg['To'] = _format_addr('管理员 <%s>' % to_addr)
msg['Subject'] = Header('来自SMTP的问候……', 'utf-8').encode()
# 邮件正文是MIMEText:
msg.attach(MIMEText('send with file...', 'plain', 'utf-8'))
# 发送附件图片
with open(r'D:\360yun\360yun\code\code_others\jiang_ML\model.png', 'rb') as f:
att1 = MIMEText(f.read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; filename="model.png"'
msg.attach(att1)
# 发送EXCEL附件
with open(r'D:\360yun\360yun\code\code_research\tsh_NLP\re_result_train.xlsx', 'rb') as f:
att2 = MIMEText(f.read(), 'base64', 'utf-8')
att2["Content-Type"] = 'application/octet-stream'
att2["Content-Disposition"] = 'attachment; filename="test.xlsx"'
msg.attach(att2)
# # 添加附件就是加上一个MIMEBase,从本地读取一个图片:
# with open(r'D:\360yun\360yun\code\code_others\jiang_ML\model.png', 'rb') as f:
# # 设置附件的MIME和文件名,这里是png类型:
# mime = MIMEBase('image', 'png', filename='test.png')
# # 加上必要的头信息:
# mime.add_header('Content-Disposition', 'attachment', filename='test.png')
# mime.add_header('Content-ID', '<0>')
# mime.add_header('X-Attachment-Id', '0')
# # 把附件的内容读进来:
# mime.set_payload(f.read())
# # 用Base64编码:
# encoders.encode_base64(mime)
# # 添加到MIMEMultipart:
# msg.attach(mime)
server = smtplib.SMTP(smtp_server, 25)
# server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
print('Your email send sucessful!')
server.quit()
Your email send sucessful!
(221, b'Bye.')
图片在正文
大部分服务商都会屏蔽带有外链的图片,需要以附件的形式附送,然后添加到正文中,通过src=cid:0就可以引用,不同图片可以依次编号进行引用
from email import encoders
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
from email.mime.multipart import MIMEMultipart, MIMEBase
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, 'utf-8').encode(), addr))
# 输入Email地址和口令
from_addr = '1185725270@qq.com'
password = 'ainiajweovxdhifc'
# 输入收件人地址
to_addr = 'xt_shaohan@163.com'
# 输入SMTP服务器地址
smtp_server = 'smtp.qq.com'
# 邮件对象:
msg = MIMEMultipart()
msg['From'] = _format_addr('Python爱好者 <%s>' % from_addr)
msg['To'] = _format_addr('管理员 <%s>' % to_addr)
msg['Subject'] = Header('来自SMTP的问候……', 'utf-8').encode()
# 邮件正文HTML格式:
msg.attach(MIMEText('<html><body><h1>Hello</h1>' +
'<p><img src="cid:0"></p>' +
'</body></html>', 'html', 'utf-8'))
# 发送附件图片
with open(r'D:\360yun\360yun\code\code_others\jiang_ML\model.png', 'rb') as f:
att1 = MIMEText(f.read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; filename="model.png"'
att1['Content-ID'] = '<0>'
att1["X-Attachment-Id"] = '0'
msg.attach(att1)
server = smtplib.SMTP(smtp_server, 25)
# server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
print('Your email send sucessful!')
server.quit()
Your email send sucessful!
(221, b'Bye.')
兼容 txt 和 html
如果收件人无法查看 HTML 格式的邮件,就可以自动降级查看纯文本邮件
msg = MIMEMultipart(‘alternative’) msg[‘From’] = … msg[‘To’] = … msg[‘Subject’] = …
msg.attach(MIMEText(‘hello’, ‘plain’, ‘utf-8’)) msg.attach(MIMEText(’
Hello
’, ‘html’, ‘utf-8’))正常发送 msg 对象…
加密 SMTP
使用 gmail 发送
smtp_server = ‘smtp.gmail.com’ smtp_port = 587 server = smtplib.SMTP(smtp_server, smtp_port) server.starttls() # 进行加密传输
剩下的代码和前面的一模一样:
server.set_debuglevel(1)
POP3 收取邮件
SMTP 用于发送邮件,如果要收取邮件呢?
收取邮件就是编写一个MUA作为客户端,从MDA把邮件获取到用户的电脑或者手机上。收取邮件最常用的协议是POP协议,目前版本号是 3,俗称POP3。
Python 内置一个 poplib 模块,实现了 POP3 协议,可以直接用来收邮件。
注意到 POP3 协议收取的不是一个已经可以阅读的邮件本身,而是邮件的原始文本,这和 SMTP 协议很像,SMTP 发送的也是经过编码后的一大段文本。
要把 POP3 收取的文本变成可以阅读的邮件,还需要用email模块提供的各种类来解析原始文本,变成可阅读的邮件对象。
所以,收取邮件分两步:
第一步:用poplib把邮件的原始文本下载到本地;
第二部:用email解析原始文本,还原为邮件对象。
POP3 下载邮件
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
import poplib
# 输入邮件地址, 口令和POP3服务器地址:
email = 'xt_shaohan@163.com'
password = 'MGIUKTXPIYYPRGCR'
pop3_server = 'pop.163.com'
# 连接到POP3服务器:
server = poplib.POP3(pop3_server)
# 可以打开或关闭调试信息:
server.set_debuglevel(1)
# 可选:打印POP3服务器的欢迎文字:
print(server.getwelcome().decode('utf-8'))
# 身份认证:
server.user(email)
server.pass_(password)
# stat()返回邮件数量和占用空间:
print('Messages: %s. Size: %s' % server.stat())
# list()返回所有邮件的编号:
resp, mails, octets = server.list()
# 可以查看返回的列表类似[b'1 82923', b'2 2184', ...]
print(mails)
# 获取最新一封邮件, 注意索引号从1开始:
index = len(mails)
resp, lines, octets = server.retr(index)
# lines存储了邮件的原始文本的每一行,
# 可以获得整个邮件的原始文本:
msg_content = b'\r\n'.join(lines).decode('utf-8')
# 稍后解析出邮件:
msg = Parser().parsestr(msg_content)
# 可以根据邮件索引号直接从服务器删除邮件:
# server.dele(index)
# 关闭连接:
server.quit()
+OK Welcome to coremail Mail Pop3 Server (163coms[10774b260cc7a37d26d71b52404dcf5cs])
*cmd* 'USER xt_shaohan@163.com'
*cmd* 'PASS MGIUKTXPIYYPRGCR'
*cmd* 'STAT'
*stat* [b'+OK', b'1', b'2420']
Messages: 1. Size: 2420
*cmd* 'LIST'
[b'1 2420']
*cmd* 'RETR 1'
*cmd* 'QUIT'
b'+OK core mail'
解析邮件
msg = Parser().parsestr(msg_content)
# indent用于缩进显示:
def print_info(msg, indent=0):
if indent == 0:
for header in ['From', 'To', 'Subject']:
value = msg.get(header, '')
if value:
if header=='Subject':
value = decode_str(value)
else:
hdr, addr = parseaddr(value)
name = decode_str(hdr)
value = u'%s <%s>' % (name, addr)
print('%s%s: %s' % (' ' * indent, header, value))
if (msg.is_multipart()):
parts = msg.get_payload()
for n, part in enumerate(parts):
print('%spart %s' % (' ' * indent, n))
print('%s--------------------' % (' ' * indent))
print_info(part, indent + 1)
else:
content_type = msg.get_content_type()
if content_type=='text/plain' or content_type=='text/html':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
print('%sText: %s' % (' ' * indent, content + '...'))
else:
print('%sAttachment: %s' % (' ' * indent, content_type))
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
print_info(msg, indent=0)
From: t_shaohan <t_shaohan@163.com>
To: xt_shaohan@163.com <xt_shaohan@163.com>
Subject: ceshi
part 0
--------------------
Text: 后方可是否合适附近都是了积分书法家龙卷风
| |
t_shaohan
|
|
t_shaohan@163.com
|
签名由网易邮箱大师定制…
part 1
Text:
<div style="font-size:14px; padding: 0; margin:0;line-height:14px;">
<div style="padding-bottom:6px;margin-bottom:10px;border-bottom:1px solid #e6e6e6;display:inline-block;">
<a href="https://maas.mail.163.com/dashi-web-extend/html/proSignature.html?ftlId=1&name=t_shaohan&uid=t_shaohan%40163.com&iconUrl=https%3A%2F%2Fmail-online.nosdn.127.net%2Fsm6c2d99b34afb60100375ee8a3886d64b.jpg&items=%5B%22t_shaohan%40163.com%22%5D" style="display:block;background:#fff; max-width: 400px; _width: 400px;padding:15px 0 10px 0;text-decoration: none; outline:none;-webkit-tap-highlight-color:transparent;-webkit-text-size-adjust:none !important;text-size-adjust:none !important;"><table cellpadding="0" style="width: 100%; max-width: 100%; table-layout: fixed; border-collapse: collapse;color: #9b9ea1;font-size: 14px;line-height:1.3;-webkit-text-size-adjust:none !important;text-size-adjust:none !important;"><tbody style="font-family: 'PingFang SC', 'Hiragino Sans GB','WenQuanYi Micro Hei', 'Microsoft Yahei', '微软雅黑', verdana !important; word-wrap:break-word; word-break:break-all;-webkit-text-size-adjust:none !important;text-size-adjust:none !important;"><tr class="firstRow"><td width="38" style="padding:0; box-sizing: border-box; width: 38px;"><img width="38" height="38" style="vertical-align:middle; width: 38px; height: 38px; border-radius:50%;" src="https://mail-online.nosdn.127.net/sm6c2d99b34afb60100375ee8a3886d64b.jpg"></td><td style="padding: 0 0 0 10px; color: #31353b;"><div style="font-size: 16px;font-weight:bold; width:100%; white-space: nowrap; overflow:hidden;text-overflow: ellipsis;">t_shaohan</div></td></tr><tr width="100%" style="font-size: 14px !important; width: 100%;"><td colspan="2" style="padding:10px 0 0 0; font-size:14px !important; width: 100%;"><div style="width: 100%;font-size: 14px !important;word-wrap:break-word;word-break:break-all;">t_shaohan@163.com</div></td></tr></tbody></table></a>
</div>
</div>
<div style="font-size:12px;color:#b5b9bd;line-height:18px;">
<span>签名由</span><a style="text-decoration: none;color:#4196ff;padding:0 5px;" href="https://mail.163.com/dashi/dlpro.html?from=mail81">网易邮箱大师</a><span>定制</span>
</div>
</div>
</div><!--😀-->
</div>
</body>
</html>...
IMAP 收取管理邮件
基础操作
from imap_tools import MailBox, AND, MailBoxTls, MailBoxUnencrypted
# 输入邮件地址, 口令和POP3服务器地址:
# email = '1185725270@qq.com'
# password = 'ubaadytmiokrjfdd'
# imap_server = 'imap.qq.com'
email = 'shaohan.tian@hotmail.com'
password = 'tsh980509'
imap_server = 'outlook.office365.com'
## 使用163邮箱需要修改imap-tools模块
# Get date, subject and body len of all emails from INBOX folder
with MailBox(imap_server).login(email, password, initial_folder='Inbox') as mailbox:
for msg in mailbox.fetch():
print(type(msg))
print(f'''************
msg.uid -> {msg.uid}
msg.date -> {msg.date}
msg.flags -> {msg.flags}
msg.date_str -> {msg.date_str}
msg.subject -> {msg.subject}
msg.from_ -> {msg.from_}
msg.to -> {msg.to}
msg.text -> {msg.text}
msg.size -> {msg.size}
len(msg.text or msg.html) -> {len(msg.text or msg.html)}
************
''')
<class 'imap_tools.message.MailMessage'>
************
msg.uid -> 69
msg.date -> 2022-05-01 13:11:42+00:00
msg.flags -> ('\\Seen',)
msg.date_str -> Sun, 01 May 2022 13:11:42 GMT
msg.subject -> 您的电子邮件地址现已成为以下帐号的辅助邮箱: shaohan.tian.cn@gmail.com
msg.from_ -> no-reply@accounts.google.com
msg.to -> ('shaohan.tian@hotmail.com',)
msg.text -> 这是发送给 shaohan.tian.cn@gmail.com 的安全提醒的副本。
shaohan.tian@hotmail.com 是该帐号的辅助邮箱。
如果不认识此帐号,请移除
<https://accounts.google.com/AccountDisavow?adt=AOX8kioVUfFQoeKsYkX_JniZx1fdEzZKXDvHMSBobhkqrd6kAphR3XA9uzJcHZ7PrwVb4f8&rfn=2&anexp=-verified--nret-fa>
您的电子邮件地址。
[image: Google]
您的电子邮件地址已被验证为辅助邮箱
shaohan.tian.cn@gmail.com 现已将您的电子邮件地址用作其辅助邮箱。如果不认识此
帐号,您可从中移除您的电子邮件地址。
移除电子邮件地址
<https://accounts.google.com/AccountDisavow?adt=AOX8kioVUfFQoeKsYkX_JniZx1fdEzZKXDvHMSBobhkqrd6kAphR3XA9uzJcHZ7PrwVb4f8&rfn=2&anexp=-verified--nret-fa>
您也可以访问以下网址查看安全性活动:
https://myaccount.google.com/notifications
我们向您发送这封电子邮件,目的是让您了解关于您的 Google 帐号和服务的重大变
化。
© 2022 Google LLC, 1600 Amphitheatre Parkway, Mountain View, CA 94043, USA
msg.size -> 18825
len(msg.text or msg.html) -> 720
************
邮件解析
for msg in mailbox.fetch(): # generator: imaptools.MailMessage msg.uid # str | None: ‘123’ msg.subject # str: ‘some subject 你 привет’ msg.from # str: ‘Bartölke@ya.ru’ msg.to # tuple: (‘iam@goo.ru ’, ‘friend@ya.ru ’, ) msg.cc # tuple: (‘cc@mail.ru ’, ) msg.bcc # tuple: (‘bcc@mail.ru ’, ) msg.reply_to # tuple: (‘reply_to@mail.ru ’, ) msg.date # datetime.datetime: 1900-1-1 for unparsed, may be naive or with tzinfo msg.date_str # str: original date - ‘Tue, 03 Jan 2017 22:26:59 +0500’ msg.text # str: ‘Hello 你 Привет’ msg.html # str: ‘Hello 你 Привет’ msg.flags # tuple: (’\Seen’, ‘\Flagged’, ‘ENCRYPTED’) msg.headers # dict: {‘received’: (‘from 1.m.ru’, ‘from 2.m.ru’), ‘anti-virus’: (‘Clean’,)} msg.size_rfc822 # int: 20664 bytes - size info from server (*useful with headers_only arg) msg.size # int: 20377 bytes - size of received message
for att in msg.attachments: # list: imap_tools.MailAttachment
att.filename # str: 'cat.jpg'
att.payload # bytes: b'\xff\xd8\xff\xe0\'
att.content_id # str: 'part45.06020801.00060008@mail.ru'
att.content_type # str: 'image/jpeg'
att.content_disposition # str: 'inline'
att.part # email.message.Message: original object
att.size # int: 17361 bytes
msg.obj # email.message.Message: original object
msg.from_values # imap_tools.EmailAddress | None
msg.to_values # tuple: (imap_tools.EmailAddress,)
msg.cc_values # tuple: (imap_tools.EmailAddress,)
msg.bcc_values # tuple: (imap_tools.EmailAddress,)
msg.reply_to_values # tuple: (imap_tools.EmailAddress,)
# EmailAddress(name='Ya', email='im@ya.ru') # "full" property = 'Ya <im@ya.ru>'
邮件查询
# 这里有三种方法可以查询,例如查询主题为SMTP的邮件
from imap_tools import AND
with MailBox(imap_server).login(email, password) as mailbox:
mail_criteria = mailbox.fetch(AND(text='google')) # query, the str-like object
for mail in mail_criteria:
print(mail.date, mail.subject)
# mailbox.fetch('TEXT "hello"') # str
# mailbox.fetch(b'TEXT "\xd1\x8f"') # bytes, *charset arg is ignored
2022-05-01 20:40:38+08:00 欢迎使用你的新 Outlook.com 帐户
2022-05-01 13:11:01+00:00 电子邮件验证码: 750843
2022-05-01 13:11:42+00:00 您的电子邮件地址现已成为以下帐号的辅助邮箱: shaohan.tian.cn@gmail.com
from imap_tools import A, AND, OR, NOT
AND
A(text=‘hello’, new=True) # ‘(TEXT “hello” NEW)’
OR
OR(text=‘hello’, date=datetime.date(2000, 3, 15)) # ‘(OR TEXT “hello” ON 15-Mar-2000)’
NOT
NOT(text=‘hello’, new=True) # ‘NOT (TEXT “hello” NEW)’
complex
A(OR(from_=‘from@ya.ru ’, text=’“the text”’), NOT(OR(A(answered=False), A(new=True))), to='to@ya.ru ’)
python note: you can’t do: A(text=‘two’, NOT(subject=‘one’))
A(NOT(subject=‘one’), text=‘two’) # use kwargs after logic classes (args)
文件夹操作
from imap_tools import MailBox, AND
email = 'shaohan.tian@hotmail.com'
password = 'tsh980509'
imap_server = 'outlook.office365.com'
with MailBox(imap_server).login(email, password) as mailbox:
# LIST: get all subfolders of the specified folder (root by default)
for f in mailbox.folder.list():
print(f) # FolderInfo(name='INBOX|cats', delim='|', flags=('\\Unmarked', '\\HasChildren'))
# # GET: get selected folder
# current_folder = mailbox.folder.get()
# # CREATE: create new folder
# mailbox.folder.create('INBOX|folder1')
# # EXISTS: check is folder exists (shortcut for list)
# is_exists = mailbox.folder.exists('INBOX|folder1')
# # RENAME: set new name to folder
# mailbox.folder.rename('folder1', 'folder4')
# # SUBSCRIBE: subscribe/unsubscribe to folder
# mailbox.folder.subscribe('INBOX|папка два', True)
# # DELETE: delete folder
# mailbox.folder.delete('folder4')
# STATUS: get folder status info
stat = mailbox.folder.status('Notes')
print(stat) # {'MESSAGES': 41, 'RECENT': 0, 'UIDNEXT': 11996, 'UIDVALIDITY': 1, 'UNSEEN': 5}
FolderInfo(name='Archive', delim='/', flags=('\\Marked', '\\HasNoChildren'))
FolderInfo(name='Deleted', delim='/', flags=('\\Marked', '\\HasNoChildren', '\\Trash'))
FolderInfo(name='Drafts', delim='/', flags=('\\Marked', '\\HasNoChildren', '\\Drafts'))
FolderInfo(name='IMAP_TEST', delim='/', flags=('\\HasNoChildren',))
FolderInfo(name='Inbox', delim='/', flags=('\\Marked', '\\HasNoChildren'))
FolderInfo(name='Junk', delim='/', flags=('\\Marked', '\\HasNoChildren', '\\Junk'))
FolderInfo(name='Notes', delim='/', flags=('\\Marked', '\\HasNoChildren'))
FolderInfo(name='Outbox', delim='/', flags=('\\HasNoChildren',))
FolderInfo(name='Sent', delim='/', flags=('\\Marked', '\\HasNoChildren', '\\Sent'))
{'MESSAGES': 2, 'RECENT': 2, 'UIDNEXT': 42, 'UIDVALIDITY': 19, 'UNSEEN': 0}
邮件相关操作
from imap_tools import MailBox, AND, MailBoxTls, MailBoxUnencrypted
import imap_tools
email = 'shaohan.tian@hotmail.com'
password = 'tsh980509'
imap_server = 'outlook.office365.com'
# Get date, subject and body len of all emails from INBOX folder
with MailBox(imap_server).login(email, password, initial_folder='IMAP_TEST') as mailbox:
pass
# # COPY all messages from current folder to Junk
# mailbox.copy(mailbox.uids(), 'IMAP_TEST')
# MOVE messages with uid in 5,10 from current folder to INBOX/folder2
# mailbox.move('5, 10', 'IMAP_TEST')
# # DELETE messages with 'cat' word in its html from current folder
# mailbox.delete([msg.uid for msg in mailbox.fetch() if 'cat' in msg.html])
# # FLAG unseen messages in current folder as \Seen, \Flagged and TAG1
# flags = (imap_tools.MailMessageFlags.SEEN, imap_tools.MailMessageFlags.FLAGGED, 'TAG1')
# mailbox.flag(mailbox.uids(AND(seen=False)), flags, True)
# # APPEND: add message to mailbox directly, to INBOX folder with \Seen flag and now date
# with open('text.txt', 'rb') as f:
# msg = imap_tools.MailMessage.from_bytes(f.read()) # *or use bytes instead MailMessage
# mailbox.append(msg, 'INBOX', dt=None, flag_set=[imap_tools.MailMessageFlags.SEEN])