超参调整Wandb和Ray[tune]
Xi’an, China: ☀️ 🌡️-7°C 🌬️↘7km/h
写在前面
从深度学习模型的建立到最终作为产品服务上线,中间需要经历很多的环节,最重要的可能就是将整个模型给固定下来。构建模型过程中有很多可以调节的部分(模型架构、超参数等),并且伴随着版本的不断更迭。这里我使用wandb
作为可视化调参工具,它的主要功能包括实验追踪、数据和模型的版本管理以及模型评估,在此结合ray
强大的寻优搜索功能,补充wandb相对薄弱的部分。
超参优化流程(Hyperparameter optimization)
这里我们可以先来考虑整个超参优化的过程,如下所示:
- 构建baseline模型
- 确定超参数的搜素空间
- 确实选用的超参搜索方法
- 模型评估
常见超参优化方法如下:
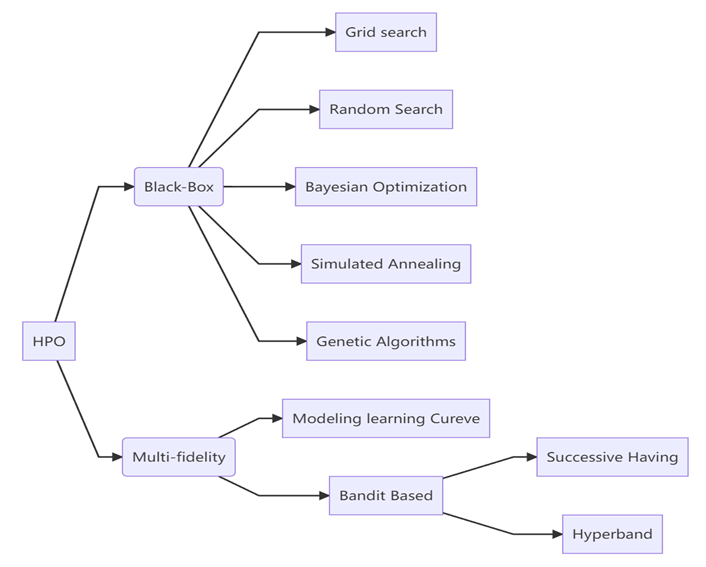 我们构造不同组别的超参数重复训练,以便于寻求:
我们构造不同组别的超参数重复训练,以便于寻求: - 哪个超参数对模型的影响最重要
- 哪个超参数对模型的影响更敏感
- 哪个超参数对模型的适用性更强 当然,在整个重复训练的过程需要注意:
- Python环境的变化
- 随机种子的设置
- 模型版本的管理
wandb入门
注册wandb
- 在https://wandb.ai/site 注册个人账户;
- 使用
pip install wandb安装wandb库 - 在命令行输入
wandb login,使用申请到的API key 进行登录
wandb简单示例
这里一个入门的示例,用config表示超参数空间中得到的1组参数,方便起见,这里提交了3组相同参数在模型中运行的结果,每个模型训练5个epoch,主要记录训练过程中loss和acc两个参数的变化,dashboard上显示loss.min以及acc.max。当acc<5的时候,会以邮件形式通知,发出警示,更多用法可查阅wandb官方Documentation
,示例代码如下:
import time
import wandb
import random
from wandb import AlertLevel
# 设置一组超参数
config = {
"lr":0.1,
"layers":15
}
# 假设有3组超参数相同
for i in range(3):
"""
wandb初始化
project->项目名称
mode->运行模式,分为'online'、'offline'以及'disable',str类型
sync_tensorboard->是否同步到tensorboard,bool类型
config->记录的一组超参数,dict类型
reinit->是否允许在同一个进程中调用多个wand.init(),bool类型
"""
run = wandb.init(
project="wandb_test",
mode="online",
sync_tensorboard=False,
config=config,
reinit=True
)
# 设置单次运行的名称(不设置会随机赋予)以及标签(主要用于建立分组)
wandb.run.name = f"run_{i}"
wandb.run.tags=["test"]
# 自定义单次run的衡量指标
wandb.define_metric("loss", summary="min")
wandb.define_metric("acc", summary="max")
for epoch in range(5):
loss = random.randint(1,10)
acc = random.randint(1,10)
# 设置单个衡量指标阈值,超出则发出警告邮件
# 存在AlertLevel.WARN, AlertLevel.INFO, AlertLevel.ERROR
if acc < 5:
wandb.alert(
title="Low acc",
text=f"Acc{acc} is below the acceptable theshold, i{i}",
level=AlertLevel.WARN,
wait_duration=300
)
time.sleep(5) # 防止网络阻塞
# 记录需要展示在dashboard上的数据列
wandb.log({
"loss":loss,
"acc":acc
})
run.finish() # 单次run结束
注意:wandb.alert操作需要再个人主页设置中打开警示通知操作,在上述代码实际过程中,Alert邮件只发送了一次,猜测可能发生了阻塞或其它,可使用IMOP或POP3自己进行设置。进入wandb首页https://wandb.ai/home
对应项目,查看workspace及table如下:

离线使用
在大多数情况下,训练大模型需要在超算服务器上运行,一般运行过程中,为了节省成本、减少时间开销以及增强稳定性,计算节点一般都不会设置网络,我们需要将wandb的log先暂时离线保存,随后再进行上传,wandb也提供了这种功能的。 将3.2节代码修改为离线模式示例:
import wandb
config = {
"lr":0.1,
"layers":15
}
for i in range(3):
run = wandb.init(
project="wandb_offline",
mode="offline",
sync_tensorboard=False,
config=config,
reinit=True
)
for i in range(5):
wandb.log({
"acc":0.1,
"loss":0.2
})
run.finish()
当我们运行这段代码之后,会生成以下文件目录,其中20221220_170740正好对应每次运行的年月日_时分秒_run-id:
 同步离线run的结果,我们直接在命令行中使用
同步离线run的结果,我们直接在命令行中使用wandb,这里只举例sync部分,更多操作参阅wandb文档
,以下命令在.py文件所在目录的命令行中运行。
# 同步状态查询
[In]:wandb sync
[out]:
wandb: Number of runs to be synced: 3
wandb: wandb/offline-run-20221220_170720-3d49bs3p
wandb: wandb/offline-run-20221220_170730-1d6udhxa
wandb: wandb/offline-run-20221220_170740-1grmfhy0
wandb: NOTE: use wandb sync --sync-all to sync 3 unsynced runs from local directory.
# 同步所有runs(对应到不同的project)
wandb sync --sync-all
# 同步单次run
wandb sync [path of offline-run-2022***]
# 删除已经同步的runs
wandb sync --clean
# 同步run至project
wandb sync --sync-all -p [project_name]
wandb超参优化
在上述示例中,我们设置1组超参数数带入模型运行多个epoch查看结果,那么还添加补充超参空间设置以及超参寻优方法,整个超参调整就完成了,下面为示例代码:
import numpy as np
import random
import wandb
# � Step 1:自定义带有超参数训练的模型,返回训练过程中的acc、loss或其他指标
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch/30) + (random.random()/10))
loss = 0.2 + (1 - ((epoch-1)/10 + random.random()/5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch/20) + (random.random()/10))
loss = 0.25 + (1 - ((epoch-1)/10 + random.random()/6))
return acc, loss
def main():
# 后端运行一个wandb的进程,用于同步记录数据,此处一般不提供项目名称
run = wandb.init()
# 使用'wandb.config'代替所有需要调整的超参数
lr = wandb.config.lr
bs = wandb.config.batch_size
epochs = wandb.config.epochs
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log({
'epoch': epoch,
'train_acc': train_acc,
'train_loss': train_loss,
'val_acc': val_acc,
'val_loss': val_loss
})
# � Step 2: 确定超参数空间以及搜寻方法
# 'method'提供'random''grid'及'bayes'三种搜寻策略
sweep_configuration = {
'method': 'random',
'name': 'sweep',
'metric': {'goal': 'maximize', 'name': 'val_acc'},
'parameters':
{
'batch_size': {'values': [16, 32, 64]},
'epochs': {'values': [5, 10, 15]},
'lr': {'max': 0.1, 'min': 0.0001}
}
}
# � Step 3: 传递超参至服务器初始化sweep
sweep_id = wandb.sweep(sweep=sweep_configuration, project='my-first-sweep')
# � Step 4: 使用`wandb.agent`开始运行,'count'为运行次数
wandb.agent(sweep_id, function=main, count=4)
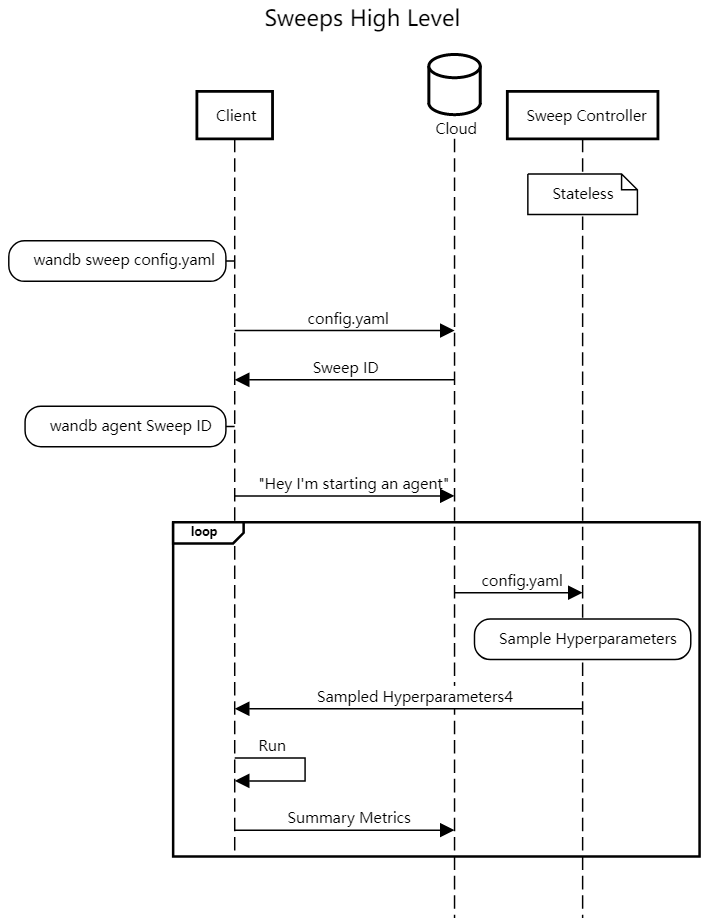
值得一提的是wandb超参调整’offline’是不可用的,也就是运行过程中需要连接网络,这是我之前提出的issue
,官方提供的sweep调用过程:
ray[tune]入门
上述超参调整过程中,wandb虽然功能很强大,但是缺少offline模式的超参调整,因此我们配合ray[tune]模块进行补充。Ray包含多个模块,功能十分强大,并且支持常见深度学习框架,文档完整。[tune]超参调整只是一部分功能,有兴趣的小伙伴可以自行探索,使用pip install ray直接进行安装。
ray直接提供了结合wandb使用的文档
,这里我将wandb超参数优化的示例3.4节代码结合ray调整为离线模式下运行:
import numpy as np
import random
import ray
from ray import air, tune
from ray.air import session
from ray.air.integrations.wandb import setup_wandb, WandbLoggerCallback
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch/30) + (random.random()/10))
loss = 0.2 + (1 - ((epoch-1)/10 + random.random()/5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch/20) + (random.random()/10))
loss = 0.25 + (1 - ((epoch-1)/10 + random.random()/6))
return acc, loss
def train_function(config):
# 超参设置相关以字典形式保留在config中
lr = config["lr"]
bs = config["bs"]
epochs = config["epochs"]
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
# 类似wandb.log部分
session.report({
'epoch': epoch,
'train_acc': train_acc,
'train_loss': train_loss,
'val_acc': val_acc,
'val_loss': val_loss
})
def tune_with_callback():
"""
构造函数使用WandbLoggerCallback()调用wandb api示例
"""
tuner = tune.Tuner(
train_function,
# TuneConfig:https://docs.ray.io/en/latest/ray-air/package-ref.html#module-ray.tune.tune_config
tune_config=tune.TuneConfig(
metric="val_acc",
mode="max",
num_samples=2, # 超参空间采样次数(注:若超参包括grid_search,总运行次数为num_sample*num_grid)
max_concurrent_trials=4 # 可并行的最大线程数
),
# RunConfig:https://docs.ray.io/en/latest/ray-air/package-ref.html#trainer
run_config=air.RunConfig(
name="tune_experiment1", # ray[tune] name,上传至wandb为group name
local_dir="./results", # log存储路径
callbacks=[
WandbLoggerCallback(
project="wandb_tune_test",
mode="offline",
tags=["tune_test"])
]
),
# Search Space API:https://docs.ray.io/en/latest/tune/api_docs/search_space.html
param_space={
"bs": tune.grid_search([16, 32, 64]),
# "bs": tune.choice([16, 32, 64]),
"lr": tune.uniform(0.0001, 0.1),
"epochs":tune.choice([5, 10, 15])
},
)
tuner.fit()
tune_with_callback()
以下是运行上述代码生成的ray相关log,此时我们需要提取wandb相关log文件,保存至./wandb路径,便于后续上传至wandb个人站点:
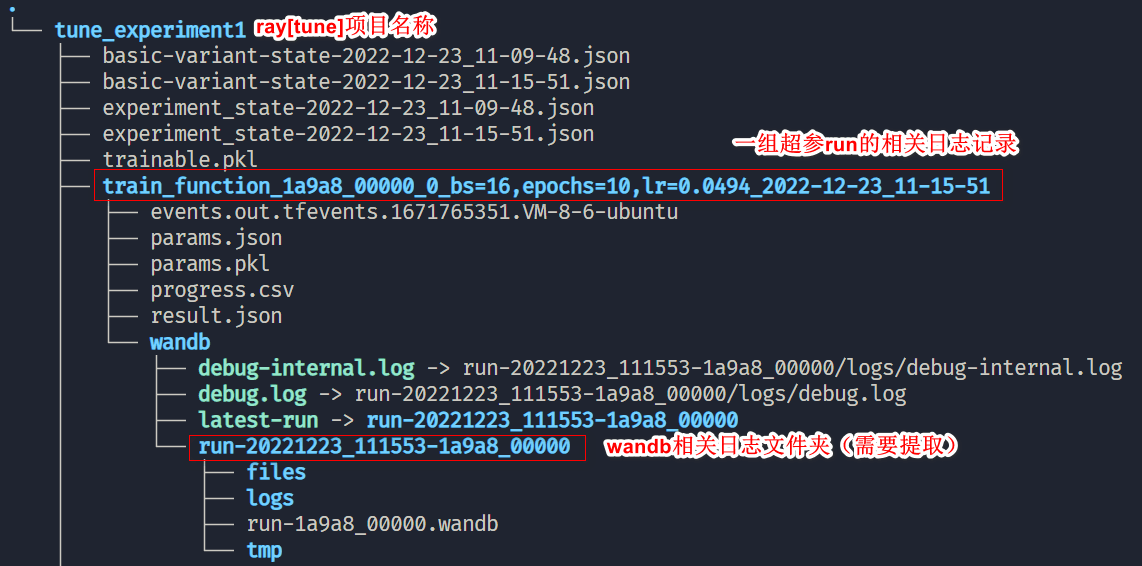 这里我写了一个简单的脚本用于提取wandb相关文件:
这里我写了一个简单的脚本用于提取wandb相关文件:
import os
import shutil
import re
def mk_sync_dir(tune_dir_path, dst="wandb"):
"""
提取ray中wandb相关run文件至./wandb
"""
for d in os.listdir(tune_dir_path):
dir_name = os.path.join(tune_dir_path,d)
if os.path.isdir(dir_name):
temp_path = os.path.join(dir_name, "wandb")
for t in os.listdir(temp_path):
if not re.findall(r"debug|latest",t):
temp_dst = os.path.join(dst, t)
src = os.path.join(temp_path, t)
shutil.copytree(src, temp_dst, dirs_exist_ok=True)
# 指定tune的项目路径
mk_sync_dir("./results/tune_experiment1")
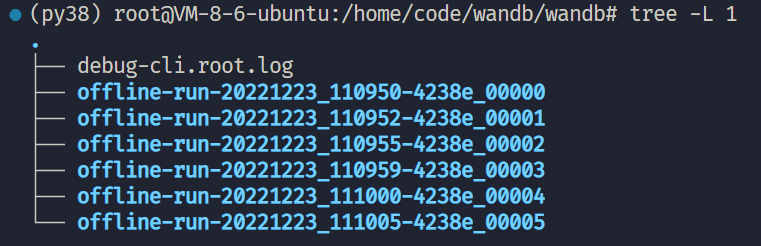
最终提取组成的wandb相关文件如下所示,然后参照3.3节正常上传即可。
参考文献: