北京超算资源简明使用指南
关于北京超算的GPU和CPU服务器的简明使用,用于提交相关计算任务

Xi’an, China: ☀️ 🌡️+6°C 🌬️↑4km/h
北京超算资源简明使用指南
要完成计算相关的任务,免不了需要使用云计算服务,有阿里云、腾讯云、京东云等,这里我们主要以北京超算提供的 CPU 和 GPU 资源为例,快速上手计算任务提交。特别建议:建立test文件夹,用于本地和云服务器上的测试,尽管北京超算提供了相关测试方法,但仍有不便。
module 工具基本命令
北京超算主要以module模块对相关软件进行管理,如果存在任何疑问或相关软件需要安装,可直接联系客服7X24h 在线。
| 命令 | 功能 | 示例 |
|---|---|---|
| module avail | 查看可用软件列表 | |
| module load [modulesfile] | 加载需要使用的软件 | module load cuda/10.0 |
| module show [modulesfile] | 查看对应软件的路径等 | module show cuda/10.0 |
| module list | 查看当前已加载软件 | |
| module unload [modulesfile] | 移除已加载软件 | module unload cuda/10.0 |
| module purge | 移除所有已加载软件 | |
| module –help | 查看 module 更多命名 |
注:可以将 load 常用软件的命令放在~/.bashrc 或者写成简单的 shell 脚本,如下:
#!/bin/bash
# CPU分区启用常用软件脚本示例
source /public1/soft/modules/module.sh
module purge
module load anaconda/3-Python3.7.3-wjl tree/1.8.0
source activate automl
conda info --envs
#!/bin/bash
# GPU分区启用常用软件脚本示例
module purge
module load anaconda/2020.11 tensorboard/2.3.0
source activate base
conda info --envs
conda 基本命令
# 加载anaconda环境
module load anaconda/2020.11
# 创建环境
conda create -n py37 python=3.7
# 已安装环境
conda env list
# conda --info envs
# 激活环境
source activate py37
# 取消激活当前环境
source deactivate py37
# 安装所需软件
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
# 查看已安装库
conda list
# 删除Python环境
conda remove --name myenv --all
conda env remove --name myenv
CPU 账户 A5 分区
系统资源说明
超算是独占节点,计费方式是以节点为基本单位。即:如果提交核数不足节点上的核数,也是按满核计费。比如:超算上每个节点有 64 核资源,提交 12 核作业,也是按照 64 核计费。所以建议满核提交,使用的核数要用一个节点核数的整数倍。
以一个节点是 64 核的超算为例,脚本里面#SBATCH -n 后面的数字要是节点数乘以每个节点的核数,才是充分利用资源。比如使用 2 个节点,可以写为SBATCH -N 2、SBATCH -n 128,我们将资源配额写到脚本里使用sbatch -p amd_256 sub.sh提交 CPU 作业。
常用软件加载脚本示例
### 4.2 CPU计算任务脚本示例
```shell
#!/bin/bash
# 设置节点数
SBATCH -N 1
# 设置节点的核数
SBATCH -n 1
# 设置分区
SBATCH -p amd_256
# 设置每个任务需要的CPU数量
SBATCH -c 64
source /public1/soft/modules/module.sh
module purge
module load ananconda/3-Python3.7.3-wjl
source activate automl
# 确保可以实时看到程序输出而不影响程序运行
export PYTHONUNBUFFERED=1
python test.py
GPU 账户 N22 分区【V100 节点】
系统资源简介
- 计算资源:每台机器配备 8 块 V100-SXM2 32GBGPU,GPU:CPU:内存比为 1GPU 卡:8CPU 核:36GB 内存。
- 存储资源:
home目录用于存放用户环境设置等文件,~/run目录读写性能较好,archive存放访问频率低的数据。
作业提交
- 命令说明:sbatch –gpus=GPU 卡数 程序运行脚本
- 命令示例:
sbatch --gpus=1 ./run.sh,其中 run.sh 脚本示例如下:
#!/bin/bash
module purge
module load anaconda/2020.11 tensorboard/2.3.0 tree/1.8.0 cudnn/8.1.1.33_CUDA11.2 cuda/11.2
source activate py39
export PYTHONUNBUFFERED=1
python test.py
高级功能:数据集存储至内存文件系统计算
- 目的:减少数据读取时间,最多程序降低 IO 瓶颈,发挥 GPU 最大性能
- 限制:1 卡最多用 36GB,8 卡最多 158GB
- 操作步骤:
- 打包数据集:
tar -cf datasets.tar datasets - 提交脚本中添加:
tar -xf datasets.tar -C /dev/shm,解压后的路径路径为/dev/shm/datasets - Python 代码的数据集路径改为
/dev/shm/datasets - sbatch 提价作业
- 打包数据集:
已提交作业管理
- 查看作业执行状态:
squeue或者parajobs,详细命令参考squeue --help作业状态参数 表示含义 JOBID 作业唯一标识号 PARTITION 作业运行使用的队列名 NAME 作业名 USER 超算账号名 ST R(Running) PD(Pending) CG(Completing) S(管理员暂时挂起) CD(Completed) F(Failed) 只有 R 状态计费 TIME 运行时间 NODES 作业使用节点数目 NODELIST(REASON) 对于 R 作业显示使用的节点列表,PD 作业显原因 - 结束作业:
scancel 作业号(JOBID)
其它常用命令
# 查看历史作业运行相关(最长时间间隔30d)
# JobID JobName Partition Account AllocCPUS State ExitCode
sacct -D -T -X -u usr_account -S 2023-05-04T00:00:00 -E 2023-05-12T00:00:00
# JobID Partition JobName User UID NNodes
# NodeList Start End Elapsed State CPUTimeRAW
sacct -u sca0076 -S 2023-05-04T00:00:00 -E 2023-05-12T00:00:00 --field=jobid,partition,jobname,user,uid,nnodes,nodelist,start,end,elapsed,state,cputimeraw -T -X
# 查看文件夹大小
du -sh /folder
# 实时(间隔0.1s)查看GPU服务器资源使用情况
watch -n 0.1 parajobs
# 查看内存占用
free -h
# 查看CPU信息
cat /proc/cpuinfo
# 查看进程
top
其它问题
Batch Script Contains DOS Line Breaks

输出 GPU 的利用率
在提交任务之前,我们一般需要查看 GPU 的显存使用情况,通过调整batch size,使整个计算任务尽最大限度“压榨”使用 GPU🛀,目前来说有以下几种方法:
parajobs
- 使用
watch -n 0.1 parajobs实时在终端中查看 GPU 的使用情况,操作比较简单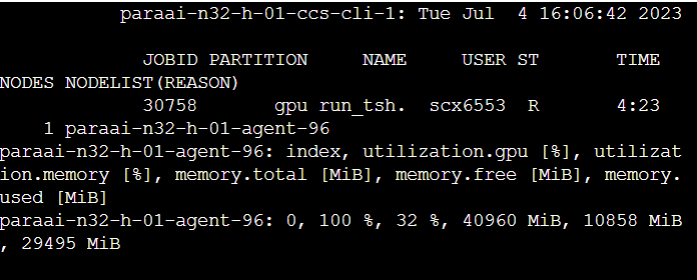
wandb
- wandb 会记录代码运行过程中资源使用情况,可以将离线输出 wnadb 的 log 文件并上传,直观对比代码运行过程中资源使用情况
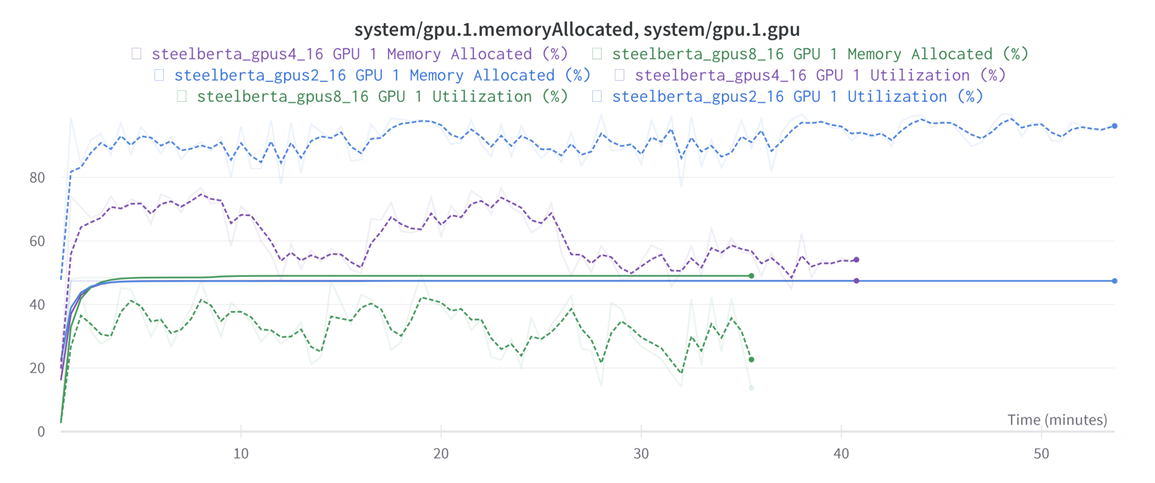
bash
- 这是 BBSC-N32-H 分区提供的代码运行过程中查看 GPU 资源使用的 bash 脚本,提交计算任务后,将得到对应任务 ID 的文件夹,其中包含一个 log 文件,记录 nvidia-smi 间隔 15 秒的输出结果
#!/bin/sh
module load anaconda/2021.11 cuda/11.3.0 cudnn/8.6.0.163_cuda11.x
source activate base
export PYTHONUNBUFFERED=1
X_LOG_DIR="log_${SLURM_JOB_ID}"
X_GPU_LOG="${X_LOG_DIR}/gpu.log"
mkdir "${X_LOG_DIR}"
function gpus_collection(){
sleep 15
process='ps -ef|grep python |grep $USER|grep -v "grep"| wc -l'
while [[ "$process?" > "0" ]]; do
sleep 1
nvidia-smi>>"$X_GPU_LOG"2>&1
echo "process num:${process}">>"${X_GPU_LOG}"2>&1
process='ps -ef| grep python | grep $USER| grep -v "grep"| wc -l'
done
}
gpus_collection &
python run.py

数据集放到内存
- BSCC-N32-H 提供内存文件系统供用户使用,可以将数据集放到内存直接读取,最大程度降低 IO 瓶颈。单卡内存 32GB。
💬 评论