实用机器学习 [draft]
【斯坦福21秋季:实用机器学习中文版】学习笔记

课程资料:
- 英文课程主页:https://c.d2l.ai/stanford-cs329p/#lectures
- bilibili视频主页:https://www.bilibili.com/video/BV13U4y1N7Uo/?spm_id_from=333.788&vd_source=410f5ed2c6c90ddf648924ab09fb7ee9
模型调参(Model tuning)
概述
常规超参数调整
-
开始于单个baseline
- 默认参数
- 论文实验部分的超参数
-
每轮调整单值
- 多轮调整查看评价指标或损失
-
多次调整重新训练模型
- 获得重要的超参数
- 超参数的敏感型(Adam优化方法泛性更好,SGD在局部区域模型结果可能比Adam更好,但不易找寻)
- 获得超参数调整范围
-
需要认真的实验数据管理
-
保存训练日志和超参数的比对、分享和重复
- 最简易的方式保存为
TXT文件或EXCEL文件以及tensorboard - 更好的选择:Streamlit(机器学习模型交互调参) 以及 Weights & Biases(机器学习版本管理,可可视化超参数组合结果)
- 最简易的方式保存为
-
保证结果可重复性
- 环境(硬件和库)
Python库对子版本兼容性维护不够 - 代码版本控制
- 随机性(随机种子设置)
- 环境(硬件和库)
超参自动调整
发展趋势:
- 计算开销下降,人力成本上升,大家更偏向于自动调参
- 自动调参结果基本可以赢过90%的数据科学家的手动调参
自动机器学习(AutoML):
- 广义定义:将整个机器学习流程自动化,包括数据清洗、特征抽取、模型选择等步骤
- 方法1:超参数优化(Hyperparameter optimization, HPO)
- 通过搜索算法优化超参数
- 方法2:神经架构搜索(Neural architecture search,NAS)
- 构建更优的网络模型
超算数优化算法(HPO)
确定搜索空间
-
确定超算搜索空间

注:log-uniform指lr取对数后的值
- 搜索空间要取得合适大小
主要算法
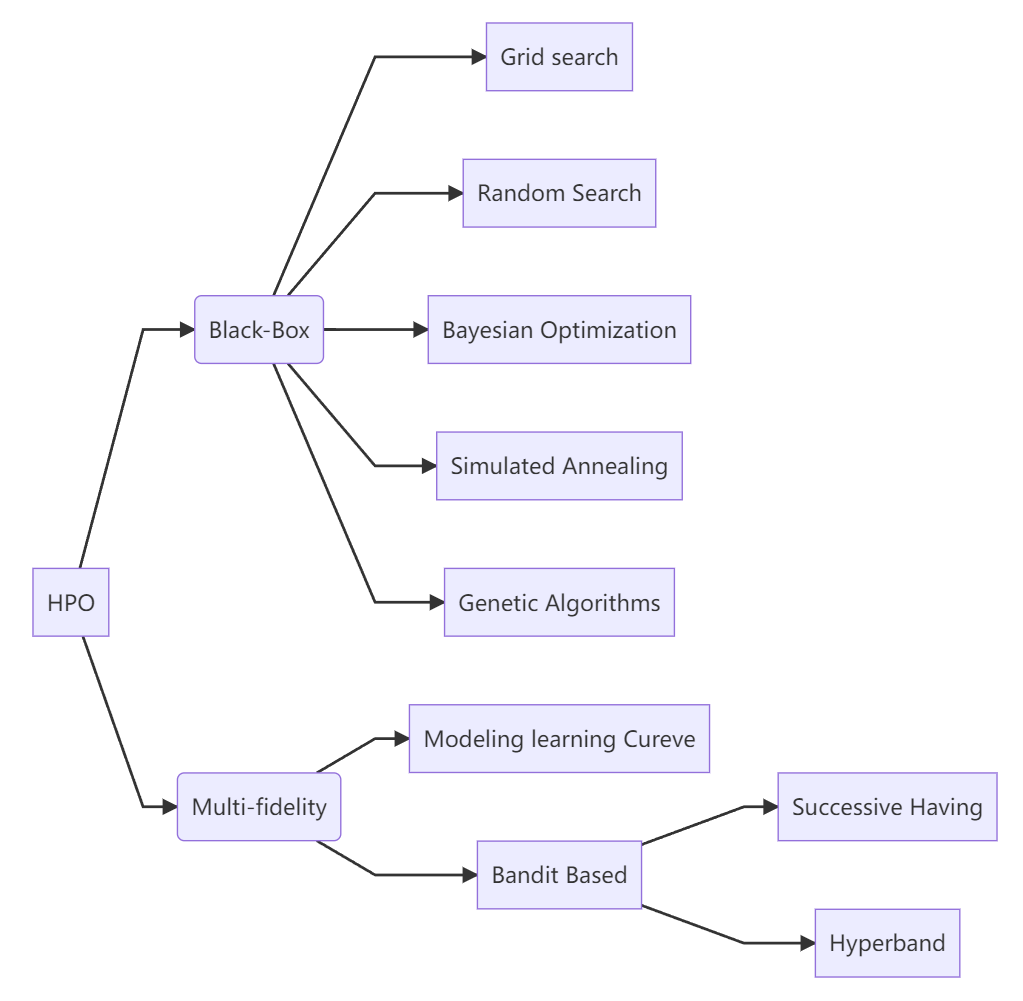
- 黑盒(Black-box):给予一组超参数,完整训练模型,在数据集上进行评估,得到对应的评价指标如$R^2$等。
- 多置信度(Multi-fidelity):对超算数进行排序
- 对数据集进行采样,变小数据集
- 模型变小,如ResNet152到RsNet18,神经网络变浅或压扁
- 根据评价指标提前终止训练
graph LR
A[HPO] -->B(Black-Box)
B --> C[Grid search]
B --> D[Random Search]
B --> E[Bayesian Optimization]
B --> F[Simulated Annealing]
B --> G[Genetic Algorithms]
A[HPO] -->H(Multi-fidelity)
H --> I[Modeling learning Curve]
H --> J[Bandit Based]
J --> K[Successive Halvng]
J --> L[Hyperband]
Grid Search:
for config in search_space:
train_and_eval(config)
return best_result
- 保证能找到最好结果
- 所有的结果都会进行评估
Random Search:
for config in range(n):
config = random_select(search_space)
train_and_eval(config)
return best_result
- 实现简单,开销相对小,可优先考虑
- 设置条件(如:Acc达到理想值或迭代一定次数后Acc不发生变化)提前终止
Bayesian Optimization:
-
BO:
- 迭代学习到从超参数到模型评估结果的一个超参数之间的function
-
Surrogate Model:
- 根据现有超参数输入和输出估算下一次采样点
-
Acquisition fuction:
- 均衡
exploration与exploitation
- 均衡
-
局限性:
- 初始和Random Search类似
- 优化过程是sequential,采样下一个点需要前一个点采样完成
- 实际应用中,当贝叶斯优化比随机搜索效果更好的时候,相对而言搭建的模型比较简单或是超参数的搜索空间比较小
SH算法(Successive Halving):
-
选择比较靠谱的超参数
-
算法细节:
- 随机选择n=16组超参数,对应训练m=25个epoch
- 将16组超参数分别训练25个epoch,分别计算评价指标
- 超算数选择评价指标选择最好的一半,epoch翻倍
- 重复2-3,直到只剩单组超参数
- 最终根据需要的epoch和budget选择n和m
Hyperband:
- 实际中用的较多
- 跑多次SH
- 每次用不同的n,m
- 更多资料参考AutoML with Successive Halfing and Hyperband 以及Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
神经架构搜索(NAS)
-
概述
- 神经网络有不同超参数
- 拓扑结构:ResNet的layers
- 全连接层存在隐藏单元大小等
- NAS能自动设计最优的神经网络架构
- 如何确定NN的搜索空间
- 如何搜索
- 如何衡量搜索结果好坏
- 神经网络有不同超参数
-
强化学习NAS
-
论文:[Neural Architecture Search with Reinforcement Learning]([1611.01578] Neural Architecture Search with Reinforcement Learning (arxiv.org) )
-
RNN控制参数输出
-
Reward是整个模型的评价指标
-
-
One-shot方法
- 训练一个较大的网络,将超参数和网络架构参数整合到其中
- 评估候选架构
- 只在意候选排序
- 跑少量的epoch
- 典例1:可微架构搜索(Differentiable Architecture Search)
- 论文:[DARTS: DIFFERENTIABLE ARCHITECTURE SEARCH](1806.09055v2.pdf (arxiv.org) )
- DARTS相对比较有竞争力
- 典例2:Scaling CNNs(CNNs优化方法
)
- 同时调整深度$\alpha^\phi$、宽度$\beta^\phi$、分辨率$\gamma^\phi$
- $\alpha \beta^2 \gamma^2 \approx 2$使得$\phi$提高2倍
-
整体研究方向
- NAS结果的可解释性
- 网络搜索架构在不同性能移动端的表现
- 整个机器学习模型更加自动化
总结
- NAS可以通过调节单个参数达到全局的优化
- NAS目前在实际中的用处
- 调整CNNs的深度,宽度以及图片分辨率
- 可导one-hot网络
神经网络微调(Deep Network Tuning)
- 深度学习是从数据获取信息的编程语言
- NN有不同的设计模式
批量和层的归一化
批量归一化(Batch Normalization)
概述:
- 对线性模型而言数据标准化可使得损失更平滑
- 平滑:$|\nabla f(\mathbf{x})-\nabla f(\mathbf{y})|^2 \leq \beta|\mathbf{x}-\mathbf{y}|^2$
- 更小的$\beta$允许更大的学习率
- 无法对整个NN起作用
- 批量归一化Batch Normalization(BN)
- 一般会使得收敛更加容易,因而可以选用更大的学习率
- 一般对最后结果不会产生太大影响,只能让其更快收敛
具体过程:

代码实现(所有代码 )
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
if not torch.is_grad_enabled(): # In prediction mode
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X - mean)**2).mean(dim=0)
else:
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean)**2).mean(dim=(0, 2, 3), keepdim=True)
X_hat = (X - mean) / torch.sqrt(var + eps)
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta
return Y, moving_mean, moving_var
层归一化(Layer Normalization)

更多归一化

总结
-
归一化可以使得层各值更加稳定,损失更加平滑,网络更加容易训练
-
一般而言不会改变其精度,但能让其快速收敛
-
Normalization常规步骤,一般BN在CNN用的多,LN在RNN用的多
💬 评论